Проблема инструментов: как проблемы надежности и масштабируемости тормозят будущее MCP и агентного ИИ
Цель общих ИИ-агентов — коренным образом изменить наши отношения с технологиями. Мы представляем себе будущее, в котором ИИ не просто дает ответы, а действует как способный партнер — бронирует поездки, управляет сложными проектами и беспрепятственно координирует задачи во всех приложениях, которые мы используем ежедневно. Двигателем этой революции является «использование инструментов», когда ИИ-агенты подключаются к внешним приложениям и управляют ими через API. Model Context Protocol (MCP), открытый стандарт, разработанный как «USB для ИИ», стал «стандартной» основой для этой совместимости, создав универсальный язык для общения агентов и инструментов.
Однако, прежде чем ИИ-агенты смогут стать надежной частью нашей повседневной жизни, индустрия должна преодолеть серьезное и неотложное узкое место: двойной кризис надежности и масштабируемости инструментов.
С повседневной точки зрения эта проблема проста: если ИИ-агенту нельзя доверять выполнение задачи правильно каждый раз, люди не будут им пользоваться. Если вы попросите агента забронировать рейс, и он потерпит неудачу в одном из трех случаев, вы быстро вернетесь к самостоятельному бронированию. Для корпораций ставки еще выше; ненадежность недопустима для критически важных рабочих процессов. Более того, если агент может подключиться только к нескольким инструментам, прежде чем его производительность ухудшится — проблема масштабируемости — он навсегда останется нишевым гаджетом, неспособным справиться с огромными и разнообразными вариантами использования, которые сделали бы его по-настоящему преобразующим. Чтобы ИИ-агенты превратились из новинки в незаменимую утилиту, они должны быть как надежными, так и способными расти вместе с нашими потребностями.
Погружение в двойной кризис: надежность и масштабируемость
Проблема инструментов проявляется в виде двух различных, но тесно взаимосвязанных проблем: надежности и масштабируемости. Хотя они и связаны, они представляют собой разные аспекты одного и того же основного архитектурного сбоя.
Во-первых, существует проблема надежности: фундаментальная неспособность агента правильно и последовательно использовать инструменты, даже с ограниченным набором. Это вопрос базового доверия. Бенчмарк MCP-Universe, комплексная система для оценки производительности агентов, предоставляет убедительные эмпирические доказательства этого кризиса. Он тестирует агентов на сложных, многоэтапных задачах, требующих долгосрочного планирования и использования больших, незнакомых наборов инструментов.
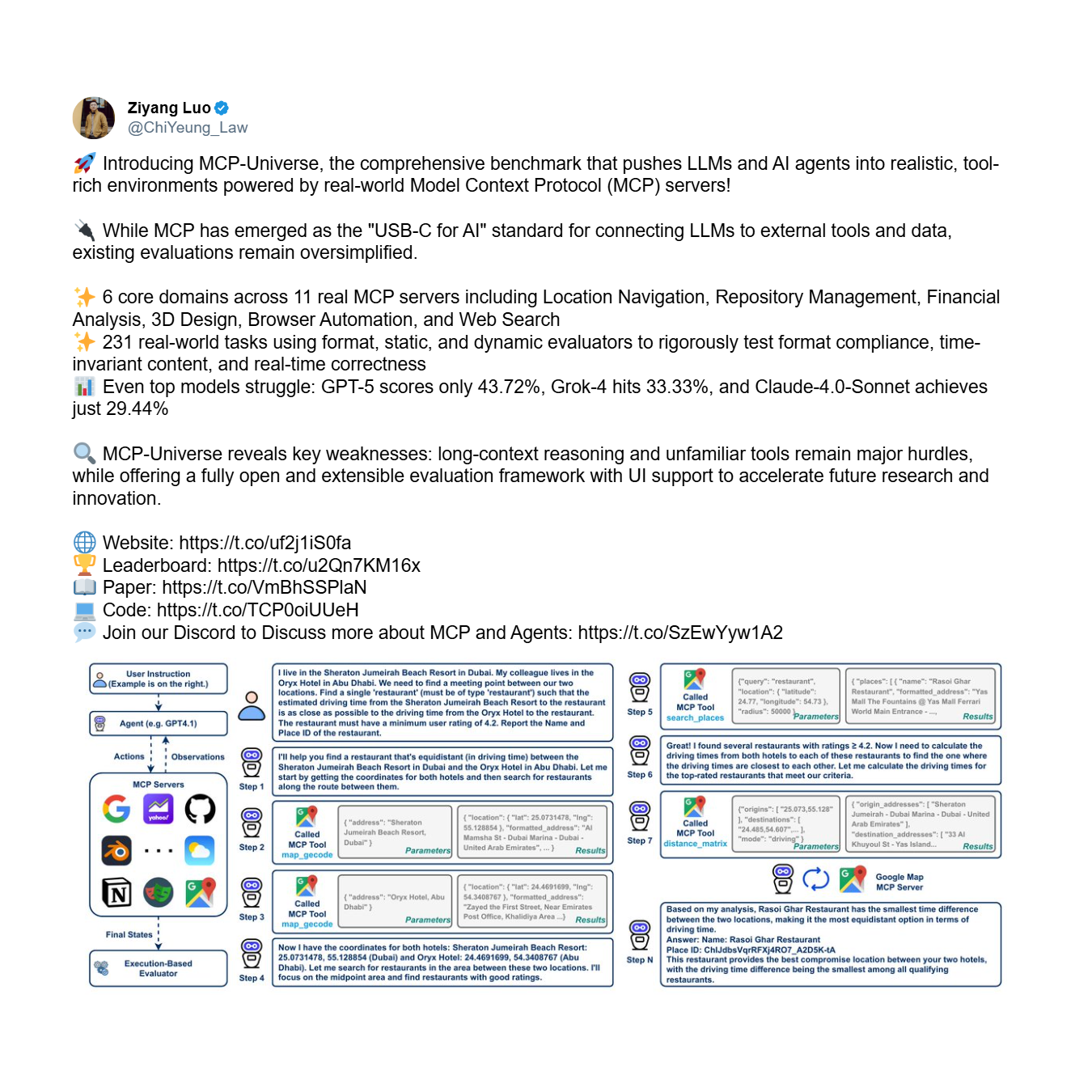
Результаты отрезвляют. Даже самые продвинутые модели терпят впечатляющие неудачи, демонстрируя системную неспособность надежно использовать инструменты.
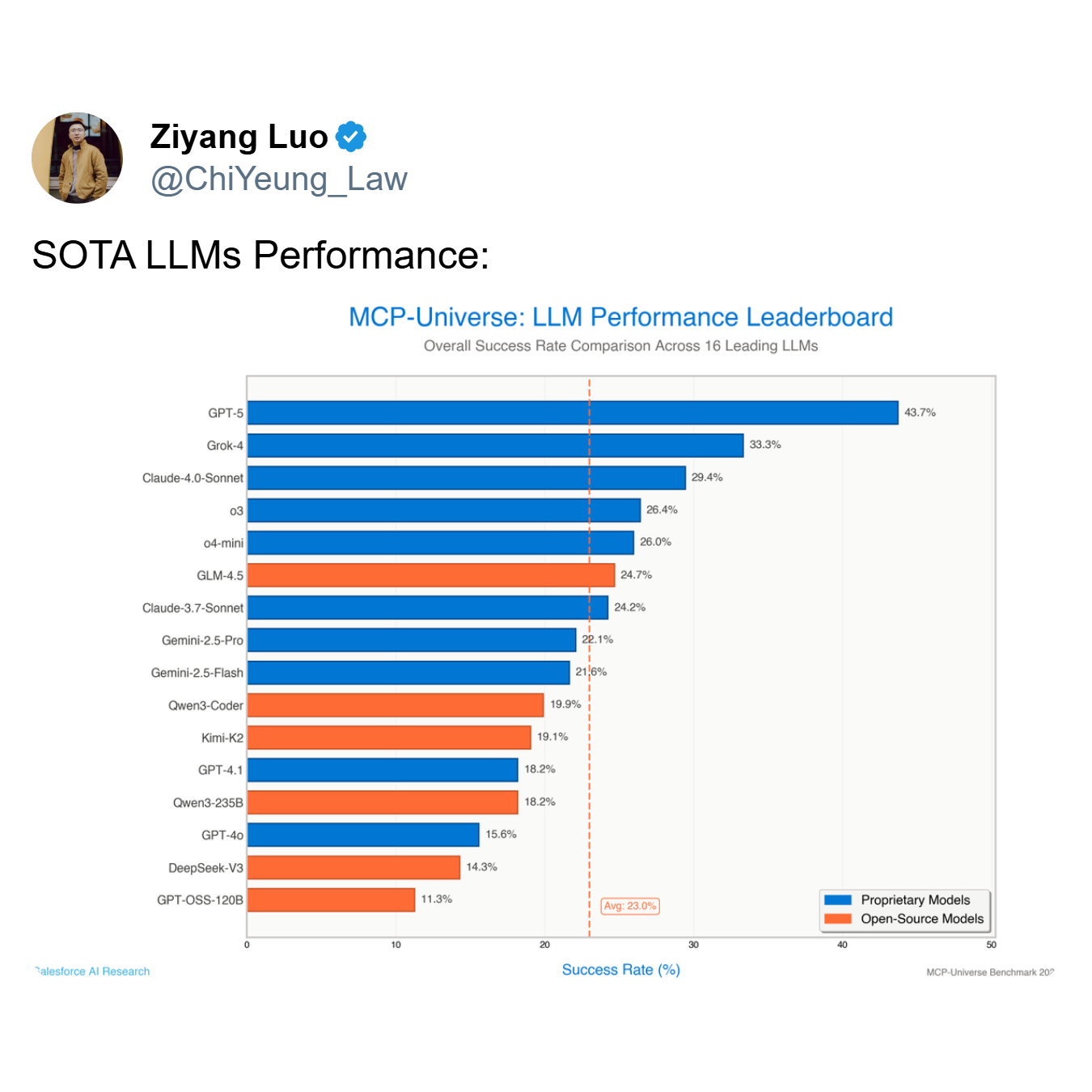
Как показывает таблица лидеров, самая производительная модель, GPT-5, достигает показателя успеха всего в 43,7%, в то время как средний показатель по всем 16 ведущим моделям падает до всего лишь 23,0%. Агент, который терпит неудачу более чем в половине случаев — как это делают ведущие модели, такие как GPT-5 и Grok-4 (33,3% успеха) — это не полезный инструмент; это обуза.
Во-вторых, существует проблема масштабируемости. Это задача поддержания производительности по мере расширения числа доступных инструментов с десятков до сотен или даже тысяч. Агент может быть умеренно надежным с 5 инструментами, но полностью выйти из строя при наличии 50. Для предприятия, внедряющего MCP, где количество интегрированных сервисов может расти экспоненциально, это критическая и неотложная проблема. Как отметил Шалев Шалит с Саммита разработчиков MCP, управление этой «перегрузкой инструментами» является основным препятствием для организаций, стремящихся развертывать ИИ-агентов в больших масштабах.
Первопричина: архитектурный недостаток монолитных агентов
Этот повсеместный сбой не случаен; он проистекает из конкретных, идентифицируемых ограничений в доминирующей парадигме одного агента, одной модели. В этой архитектуре на одну монолитную большую языковую модель (LLM) возлагается вся когнитивная нагрузка: интерпретация намерения пользователя, определение правильного инструмента, форматирование вызова API, выполнение действия и анализ результата. Этот подход в корне хрупок и плохо приспособлен к реальной сложности, что напрямую ведет к кризисам надежности и масштабируемости по следующим причинам:
- Ограничение контекстного окна: У LLM есть конечное контекстное окно, которое является «рабочей памятью», где они хранят запрос пользователя, историю разговора и схемы доступных инструментов. По мере добавления новых инструментов их определения быстро заполняют это ограниченное пространство, оставляя мало места для самого процесса рассуждения. Модель вынуждена «забывать» или упускать из виду критические детали, что приводит к ошибкам.
- Когнитивная перегрузка: Даже с большим контекстным окном, требование от одной модели быть экспертом во всем создает когнитивную перегрузку. Модель должна одновременно интерпретировать намерение, искать в обширной библиотеке инструментов, различать тонкие различия в API (например,
create_eventиupdate_event), генерировать точный синтаксис и обрабатывать ошибки. Эта многозадачная нагрузка снижает качество ее «мышления» и приводит к плохим решениям. - Неспособность к обобщению на невиданные инструменты: Монолитные модели с трудом используют инструменты, на которых они не были явно обучены. Им не хватает внутренней способности понимать функцию нового инструмента только по его схеме, что часто приводит к галлюцинациям параметров, использованию инструмента не по назначению или полному отказу от его использования.
Новая парадигма от Jenova: решение проблемы с помощью мультиагентной архитектуры
Решение этой проблемы с инструментами требует фундаментального архитектурного сдвига от монолитной модели. Это подход, впервые предложенный Jenova, которая занимается этой конкретной проблемой с начала прошлого года, задолго до того, как «инструменты» стали мейнстримом. Jenova осознала, что истинная масштабируемость и надежность не могут быть достигнуты только за счет простых архитектурных или системных инноваций. Вместо этого потребовались годы накопленного инженерного опыта и знаний, одержимо сфокусированных на одной цели: сделать так, чтобы мультиагентные архитектуры использовали инструменты надежно и масштабируемо.
Эта новая парадигма, основанная на собственной системе мультиагентной смеси экспертов (MoE), была разработана для решения проблем надежности и масштабируемости. Вот технический разбор того, как архитектура Jenova, рожденная годами целенаправленной инженерной работы, решает проблему:
- Маршрутизация «Смесь экспертов» (MoE): При получении сложного запроса система использует сложный уровень маршрутизации. Этот маршрутизатор сначала классифицирует намерение пользователя в определенную область. Например, некоторые модели высоко специализированы на областях поиска информации, превосходно понимая запросы и используя поисковые инструменты. Другие оптимизированы для областей, ориентированных на действия, и умело выполняют такие задачи, как составление электронных писем или создание приглашений в календарь. Третья категория может специализироваться на аналитических областях, занимаясь обработкой данных и логическими рассуждениями. Затем запрос направляется к специализированному агенту, наиболее подходящему для этой конкретной области, что гарантирует, что самая квалифицированная модель обработает каждую часть задачи.
- Оркестровка нескольких моделей: Поскольку модели из разных лабораторий (таких как OpenAI, Google и Anthropic) обучаются на разных данных и архитектурах, они развивают различные специализации, которые соответствуют этим областям. Например, модель, интенсивно обученная на веб-данных, может быть лучше для области поиска информации, в то время как другая модель, доработанная для следования инструкциям, может преуспеть в области, ориентированной на действия. Оптимальная мультиагентная архитектура должна обладать гибкостью, чтобы использовать это разнообразие, используя лучшую модель для каждой конкретной области, а не быть привязанной к экосистеме одной компании. Система Jenova интеллектуально распределяет наиболее подходящий LLM для каждой задачи, обеспечивая пиковую производительность и надежность на каждом этапе рабочего процесса.
- Контекстное ограничение инструментов и загрузка «точно в срок»: Для решения проблемы ограничения контекстного окна и масштабируемости архитектура использует подход к загрузке инструментов «точно в срок». Вместо того чтобы забивать контекст агента всеми доступными инструментами, система использует адаптивные протоколы маршрутизации для прогнозирования наиболее вероятного набора инструментов, необходимых для текущего графа задач. В активный контекст агента загружаются только схемы этого релевантного подмножества, что сохраняет процесс рассуждения чистым и сфокусированным. Это значительно снижает накладные расходы на токены и позволяет системе масштабироваться до тысяч потенциальных инструментов без снижения производительности.
Эффективность этого подхода подтверждается реальными показателями производительности Jenova. Она сообщает о 97,3% успешности использования инструментов. Важно отметить, что это не цифра из контролируемого бенчмарка или доработанной лабораторной среды. Это показатель, отражающий производительность в реальных условиях, в разнообразном и неконтролируемом ландшафте тысяч пользователей, взаимодействующих с множеством серверов и инструментов MCP.
Достижение такого уровня надежности — это не просто результат сложной архитектуры. Самая сложная часть создания по-настоящему масштабируемой агентной системы — это обеспечение бесперебойной работы бесконечного числа разнообразных инструментов с разными моделями из разных лабораторий, каждая из которых обучена на разных данных. Это создает астрономически сложную матрицу совместимости. Решение этой задачи аналогично созданию реактивного двигателя: иметь чертеж — это одно, но производство надежного, высокопроизводительного двигателя, работающего в реальных условиях, требует многолетнего специализированного опыта, итераций и глубоких, накопленных инженерных знаний. Эта проверенная в производстве надежность — то, что действительно отличает теоретический проект от функциональной системы корпоративного уровня.
Этот прорыв был признан ключевыми фигурами в сообществе ИИ. Даррен Шепард, видный идейный лидер и создатель сообщества в экосистеме MCP, соучредитель Acorn Labs и создатель широко используемого дистрибутива Kubernetes k3s, отметил, что эта архитектура эффективно решает основную проблему.

Заключение: архитектурный императив для будущего агентного ИИ
Эмпирические данные и архитектурные принципы приводят к неоспоримому выводу: будущее способных, надежных и масштабируемых ИИ-агентов не может быть монолитным. Преобладающая парадигма одной модели является прямой причиной проблемы с инструментами, которая в настоящее время тормозит прогресс экосистемы MCP и агентного ИИ в целом.
Хотя многие в отрасли пытаются решить эту проблему со стороны сервера, этот подход в корне ошибочен, поскольку он не решает основную проблему ограниченной когнитивной способности агента. Истинное решение должно быть ориентировано на агента. Как показывает успех Jenova, решение этой проблемы возможно, но оно требует гораздо большего, чем простое улучшение базовых возможностей моделей или добавление легкого логического слоя. Оно требует смены парадигмы в сторону сложных, ориентированных на агента архитектур, построенных на глубоких, накопленных инженерных и архитектурных знаниях, специально сфокусированных на уникальных проблемах агентных систем.