ツールのボトルネック:信頼性とスケーラビリティの課題がMCPとエージェントAIの未来をいかに停滞させているか
汎用AIエージェントの目標は、テクノロジーとの関係を根本的に変えることです。AIが単に答えを提供するだけでなく、有能なパートナーとして機能する未来を私たちは思い描いています。旅行の予約、複雑なプロジェクトの管理、そして私たちが日常的に使用するすべてのアプリ間でタスクをシームレスに調整するなどです。この革命を推進するエンジンは「ツール利用」であり、AIエージェントはAPIを介して外部アプリケーションに接続し、操作します。AIのためのUSBとなるべく設計されたオープンスタンダードである**Model Context Protocol (MCP)**は、この相互運用性のための「デフォルト」フレームワークとして登場し、エージェントとツールが通信するための普遍的な言語を創造しています。
しかし、AIエージェントが私たちの日常生活の信頼できる一部となる前に、業界は深刻かつ緊急のボトルネックを克服しなければなりません。それは、ツールの信頼性とスケーラビリティという二重の危機です。
日常的な視点から見ると、この問題は単純です。AIエージェントが毎回タスクを正しく実行すると信頼できなければ、人々はそれを使わなくなります。エージェントにフライトの予約を頼んで3回に1回失敗するなら、すぐに自分で予約するようになるでしょう。企業にとっては、さらに大きなリスクが伴います。信頼性の欠如は、ミッションクリティカルなワークフローにとっては論外です。さらに、エージェントがパフォーマンスが低下する前に数個のツールにしか接続できない場合(スケーラビリティの問題)、それは永遠にニッチなガジェットであり続け、真に変革をもたらすであろう広大で多様なユースケースを処理することはできません。AIエージェントが目新しさから不可欠なユーティリティへと移行するためには、信頼性が高く、私たちのニーズと共に成長できる能力が必要です。
二つの危機への深掘り:信頼性とスケーラビリティ
ツールのボトルネックは、信頼性とスケーラビリティという、2つの異なるが深く絡み合った問題として現れます。これらは関連していますが、同じ核心的なアーキテクチャの失敗の異なる側面を表しています。
第一に、信頼性の問題があります。これは、限られたツールセットであっても、エージェントがツールを正しく一貫して使用できないという根本的な能力の欠如です。これは基本的な信頼性の問題です。エージェントのパフォーマンスを評価するための包括的なフレームワークであるMCP-Universeベンチマークは、この危機の明白な経験的証拠を提供します。これは、長期的な推論と大規模で未知のツールセットの使用を必要とする複雑なマルチステップタスクでエージェントをテストします。
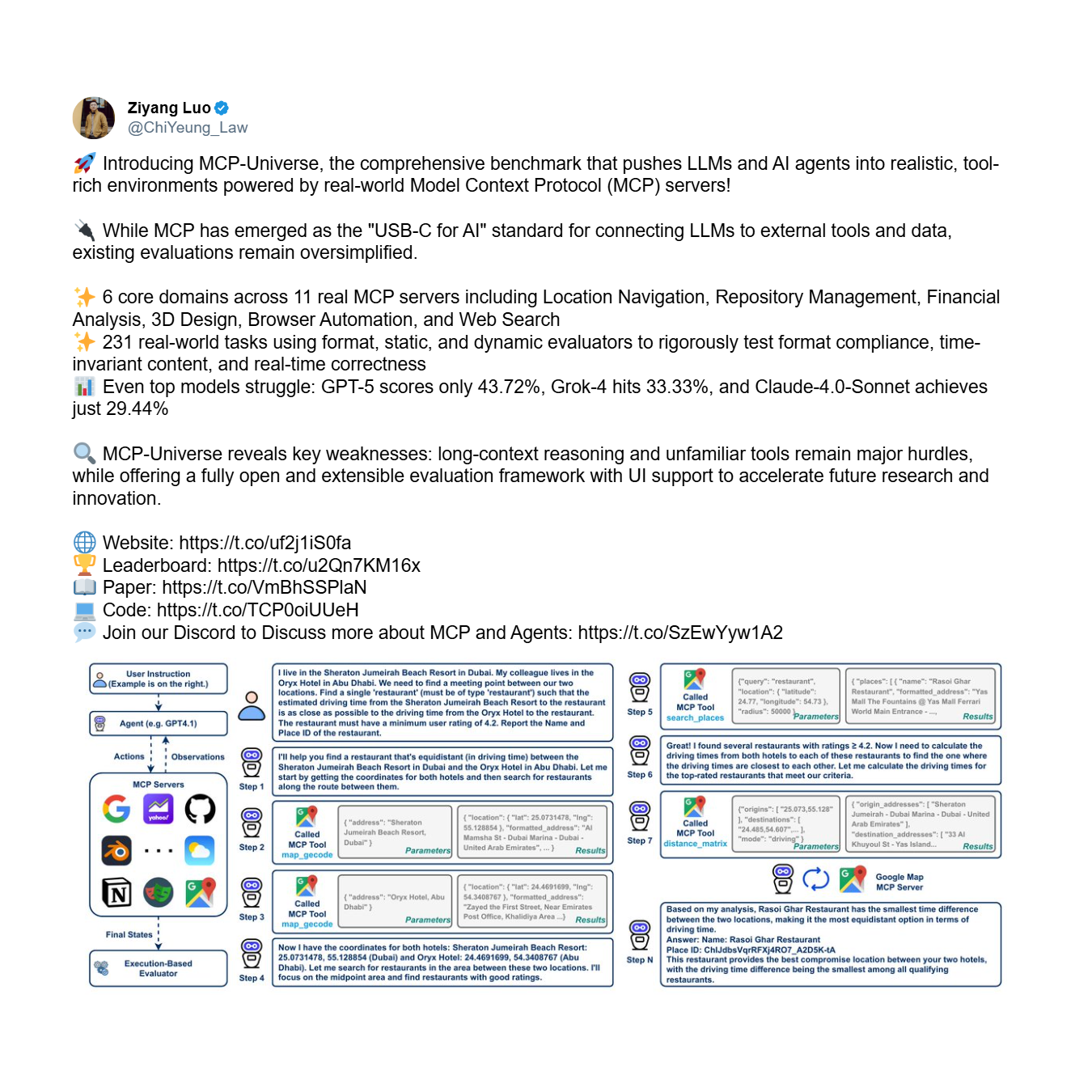
その結果は sobering です。最も先進的なモデルでさえ見事に失敗し、ツールを確実に使用する体系的な能力の欠如を露呈しています。
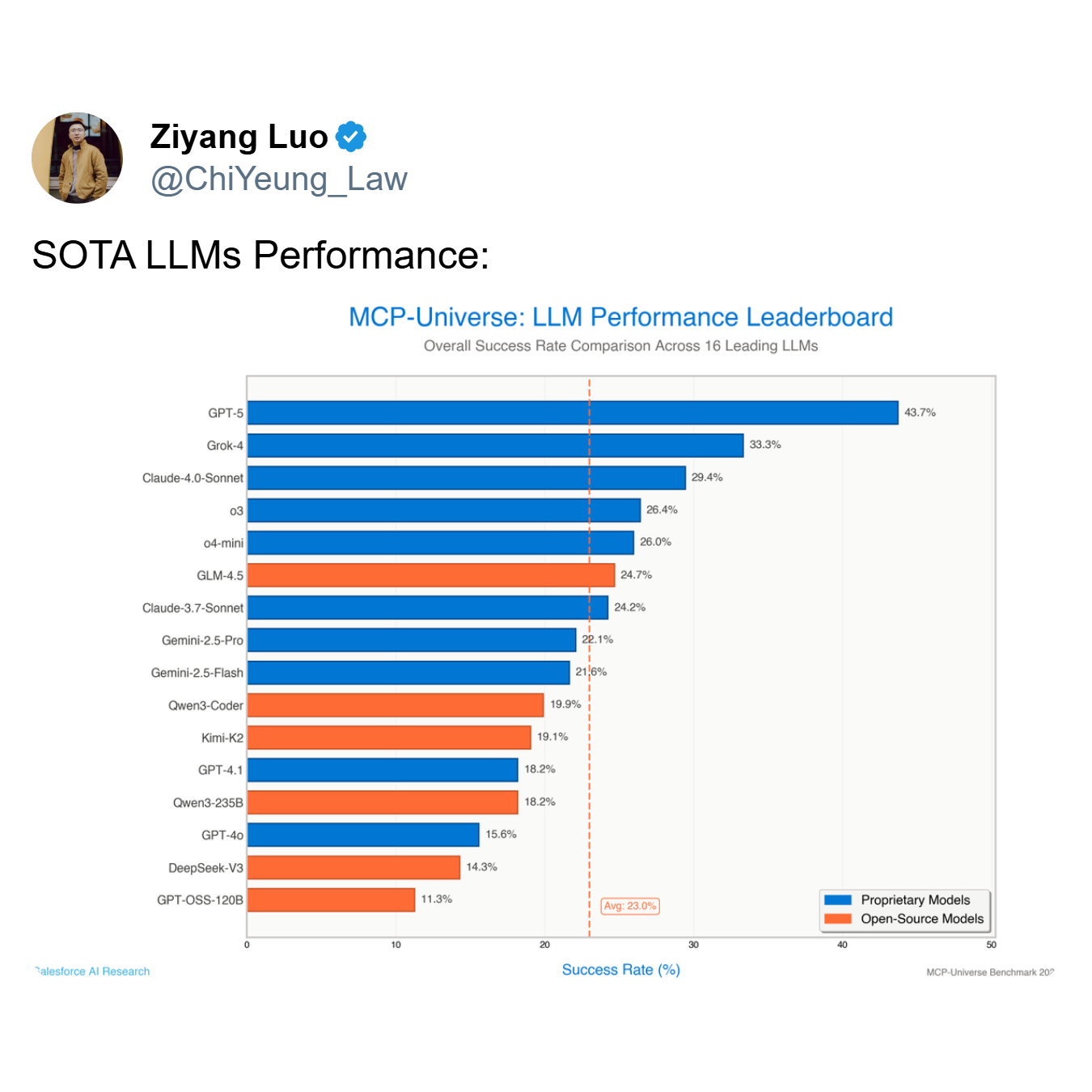
リーダーボードが示すように、最もパフォーマンスの高いモデルであるGPT-5の成功率はわずか**43.7%であり、16の主要モデル全体の平均はわずか23.0%**にまで急落します。GPT-5やGrok-4(成功率33.3%)のようなトップモデルのように、半分以上の確率で失敗するエージェントは、有用なツールではなく、負債です。
第二に、スケーラビリティの問題があります。これは、利用可能なツールの数が数十から数百、さらには数千に拡大するにつれてパフォーマンスを維持するという課題です。エージェントは5つのツールではそこそこ信頼できるかもしれませんが、50のツールを提示されると完全に崩壊する可能性があります。統合されるサービスの数が指数関数的に増加する可能性のあるMCPを導入する企業にとって、これは重大かつ差し迫った懸念です。MCP開発者サミットのShalev Shalit氏が指摘したように、この「ツールの過負荷」を管理することは、AIエージェントを大規模に展開しようとする組織にとって主要な障害です。
根本原因:モノリシックエージェントのアーキテクチャ上の欠陥
この広範な失敗は任意のものではありません。それは、支配的な単一エージェント、単一モデルのパラダイム内の特定の、識別可能な制限に起因します。このアーキテクチャでは、1つのモノリシックな大規模言語モデル(LLM)が、ユーザーの意図の解釈、正しいツールの特定、APIコールのフォーマット、アクションの実行、結果の解析という認知的な作業負荷全体を担います。このアプローチは根本的に脆弱であり、現実世界の複雑さに対応するには不十分であり、以下の理由から信頼性とスケーラビリティの危機に直接つながります。
- コンテキストウィンドウの制限: LLMには有限のコンテキストウィンドウがあり、これはユーザーのクエリ、会話履歴、利用可能なツールのスキーマを保持する「作業メモリ」です。ツールが追加されるにつれて、その定義がこの限られたスペースをすぐに飽和させ、実際の推論プロセスにほとんど余裕がなくなります。モデルは重要な詳細を「忘れる」か見落とすことを余儀なくされ、エラーにつながります。
- 認知的過負荷: 大きなコンテキストウィンドウがあっても、単一のモデルにすべてのエキスパートであることを求めることは、認知的過負荷を生み出します。モデルは、意図を解釈し、広大なツールライブラリを検索し、微妙に異なるAPI(例:
create_eventvsupdate_event)を区別し、正確な構文を生成し、エラーを処理することを同時に行わなければなりません。このマルチタスクの負担は、その「思考」の質を低下させ、不適切な意思決定につながります。 - 未知のツールへの汎化能力の欠如: モノリシックモデルは、明示的にトレーニングされていないツールの使用に苦労します。スキーマだけから新しいツールの機能を本質的に理解する能力に欠けており、しばしばパラメータを幻覚したり、ツールを間違った目的で使用したり、まったく使用できなかったりします。
Jenovaからの新しいパラダイム:マルチエージェントアーキテクチャによるボトルネックの解決
このツールのボトルネックを解決するには、モノリシックモデルからの根本的なアーキテクチャの転換が必要です。これは、Jenovaが先駆けて取り組んできたアプローチであり、「ツール」が主流の概念になるずっと前の昨年初めからこの特定の問題に取り組んできました。Jenovaは、真のスケーラビリティと信頼性は、単純なアーキテクチャやシステムの革新だけでは達成できないことを認識していました。代わりに、マルチエージェントアーキテクチャがツールを確実かつスケーラブルに使用できるようにするという単一の目標に執拗に焦点を当てた、長年にわたる複合的なエンジニアリング経験と蓄積が必要でした。
この新しいパラダイムは、独自のマルチエージェント、専門家混合(MoE)システムを中心に構築されており、信頼性とスケーラビリティの両方の課題に正面から取り組むように設計されています。以下は、長年の献身的なエンジニアリングから生まれたJenovaのアーキテクチャが問題をどのように解決するかの技術的な内訳です。
- 専門家混合(MoE)ルーティング: 複雑なリクエストが受信されると、システムは洗練されたルーティング層を採用します。このルーターはまず、ユーザーの意図を特定のドメインに分類します。たとえば、一部のモデルは情報検索ドメインに高度に特化しており、クエリの理解や検索ベースのツールの使用に優れています。その他はアクション指向ドメインに最適化されており、メールの下書きやカレンダーの招待状の作成などのタスクの実行に長けています。第3のカテゴリは分析ドメインに特化し、データ処理と論理的推論を処理する場合があります。リクエストはその後、その特定のドメインに最も適した専門エージェントにルーティングされ、最も適格なモデルがタスクの各部分を処理することを保証します。
- マルチモデルオーケストレーション: OpenAI、Google、Anthropicなどの異なるラボのモデルは、異なるデータとアーキテクチャでトレーニングされているため、これらのドメインに沿った異なる専門性を発達させます。たとえば、Webデータで広範囲にトレーニングされたモデルは情報検索ドメインで優れている可能性があり、一方、指示追従のためにファインチューニングされた別のモデルはアクション指向ドメインで優れている可能性があります。最適なマルチエージェントアーキテクチャは、単一の企業のエコシステムに閉じ込められるのではなく、各特定のドメインに最適なモデルを使用する柔軟性を持っている必要があります。Jenovaのシステムは、各ジョブに最も適切なLLMをインテリジェントに割り当て、ワークフローのすべての段階で最高のパフォーマンスと信頼性を保証します。
- コンテキストに応じたツールのスコープ設定とジャストインタイムローディング: コンテキストウィンドウの制限とスケーラビリティの問題を解決するために、アーキテクチャはツールローディングに「ジャストインタイム」アプローチを採用しています。エージェントのコンテキストを利用可能なすべてのツールで溢れさせるのではなく、システムは適応型ルーティングプロトコルを使用して、現在のタスクグラフに必要なツールの最も可能性の高いセットを予測します。この関連するサブセットのスキーマのみがエージェントのアクティブなコンテキストにロードされ、推論プロセスをクリーンで集中したものに保ちます。これにより、トークンのオーバーヘッドが劇的に削減され、システムはパフォーマンスを低下させることなく数千の潜在的なツールにスケールアップできます。
このアプローチの有効性は、Jenovaの実際のパフォーマンスメトリクスによって検証されています。報告によると、ツール使用成功率は97.3%です。重要なことに、これは管理されたベンチマークやファインチューニングされたラボ環境からの数値ではありません。これは、多数のMCPサーバーやツールと対話する何千ものユーザーの多様で管理されていない環境での本番環境におけるパフォーマンスを反映したメトリクスです。
このレベルの信頼性を達成することは、単に洗練されたアーキテクチャの結果ではありません。真にスケーラブルなエージェントシステムを構築する上で最も困難な部分は、異なるデータでトレーニングされた異なるラボの異なるモデルと、無限の多様なツールがシームレスに連携することを保証することです。これは天文学的に複雑な互換性マトリックスを生み出します。これを解決することは、ジェットエンジンの製造に似ています。設計図を持つことは一つのことですが、現実世界のストレス下で機能する信頼性の高い高性能エンジンを製造するには、長年の専門知識、反復、そして深く複合的なエンジニアリング経験が必要です。この本番環境で鍛えられた堅牢性こそが、理論的な設計と機能的なエンタープライズグレードのシステムを真に分けるものです。
このブレークスルーは、AIコミュニティの主要人物によって認識されています。MCPエコシステムの著名な思想的リーダーでありコミュニティビルダーであり、Acorn Labsの共同創設者であり、広く使用されているk3s Kubernetesディストリビューションの作成者であるDarren Shepherdは、このアーキテクチャが核心的な問題を効果的に解決すると述べました。

結論:エージェントAIの未来のためのアーキテクチャ上の必須要件
経験的データとアーキテクチャの原則は、否定できない結論につながります。有能で、信頼性が高く、スケーラブルなAIエージェントの未来はモノリシックであってはなりません。普及している単一モデルのパラダイムは、現在MCPエコシステムとエージェントAI全体の進歩を停滞させているツールのボトルネックの直接的な原因です。
業界の多くはこれをサーバー側から対処しようと試みていますが、このアプローチはエージェントの限られた認知能力という核心的な問題を解決できないため、根本的に見当違いです。真の解決策はエージェント中心でなければなりません。Jenovaの成功が示すように、この問題を解決することは可能ですが、それは単にモデルの基本能力を向上させたり、軽いロジック層を追加したりするだけでは不十分です。それは、エージェントシステムの特有の課題に特化した、深く複合的なエンジニアリングとアーキテクチャの専門知識に基づいて構築された、洗練されたエージェント中心のアーキテクチャへのパラダイムシフトを要求します。