Le goulot d'étranglement de l'outillage : comment les défis de fiabilité et d'évolutivité freinent l'avenir du MCP et de l'IA agentique
L'objectif des agents d'IA généraux est de changer fondamentalement notre relation avec la technologie. Nous envisageons un avenir où l'IA ne se contente pas de fournir des réponses, mais agit comme un partenaire compétent — réservant des voyages, gérant des projets complexes et orchestrant de manière transparente les tâches sur toutes les applications que nous utilisons quotidiennement. Le moteur de cette révolution est l'« utilisation d'outils », où les agents d'IA se connectent et opèrent des applications externes via des API. Le Model Context Protocol (MCP), une norme ouverte conçue pour être l'« USB de l'IA », est devenu le cadre « par défaut » pour cette interopérabilité, créant un langage universel pour la communication entre agents et outils.
Cependant, avant que les agents d'IA puissent devenir une partie fiable de notre vie quotidienne, l'industrie doit surmonter un goulot d'étranglement grave et urgent : la double crise de la fiabilité et de l'évolutivité des outils.
Du point de vue quotidien, ce problème est simple : si un agent d'IA ne peut pas être digne de confiance pour effectuer une tâche correctement à chaque fois, les gens ne l'utiliseront pas. Si vous demandez à un agent de réserver un vol et qu'il échoue une fois sur trois, vous reviendrez rapidement à le réserver vous-même. Pour les entreprises, les enjeux sont encore plus élevés ; le manque de fiabilité est un non-sens pour les flux de travail critiques. De plus, si un agent ne peut se connecter qu'à une poignée d'outils avant que ses performances ne se dégradent — le problème de l'évolutivité —, il restera à jamais un gadget de niche, incapable de gérer les cas d'utilisation vastes et diversifiés qui le rendraient vraiment transformateur. Pour que les agents d'IA passent d'une nouveauté à une utilité indispensable, ils doivent être à la fois fiables et capables de croître avec nos besoins.
Plongée dans la double crise : fiabilité et évolutivité
Le goulot d'étranglement de l'outillage se manifeste par deux problèmes distincts mais profondément liés : la fiabilité et l'évolutivité. Bien que liés, ils représentent différentes facettes de la même défaillance architecturale fondamentale.
Premièrement, il y a le problème de la fiabilité : l'incapacité fondamentale d'un agent à utiliser les outils correctement et de manière cohérente, même avec un ensemble limité. C'est une question de confiance de base. Le benchmark MCP-Universe, un cadre complet pour évaluer les performances des agents, fournit des preuves empiriques frappantes de cette crise. Il teste les agents sur des tâches complexes en plusieurs étapes nécessitant un raisonnement à long terme et l'utilisation d'ensembles d'outils vastes et inconnus.
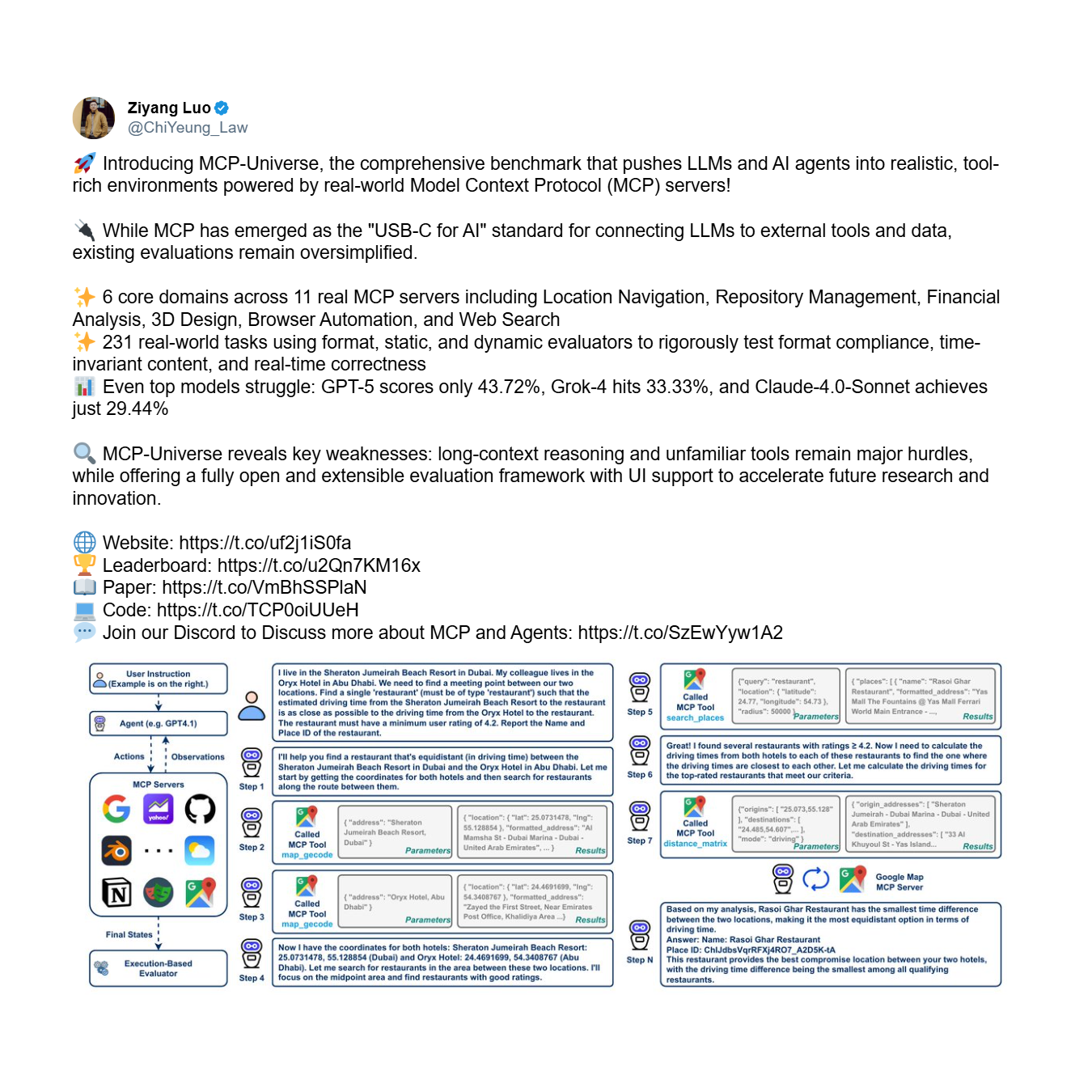
Les résultats sont décevants. Même les modèles les plus avancés échouent de manière spectaculaire, exposant une incapacité systémique à utiliser les outils de manière fiable.
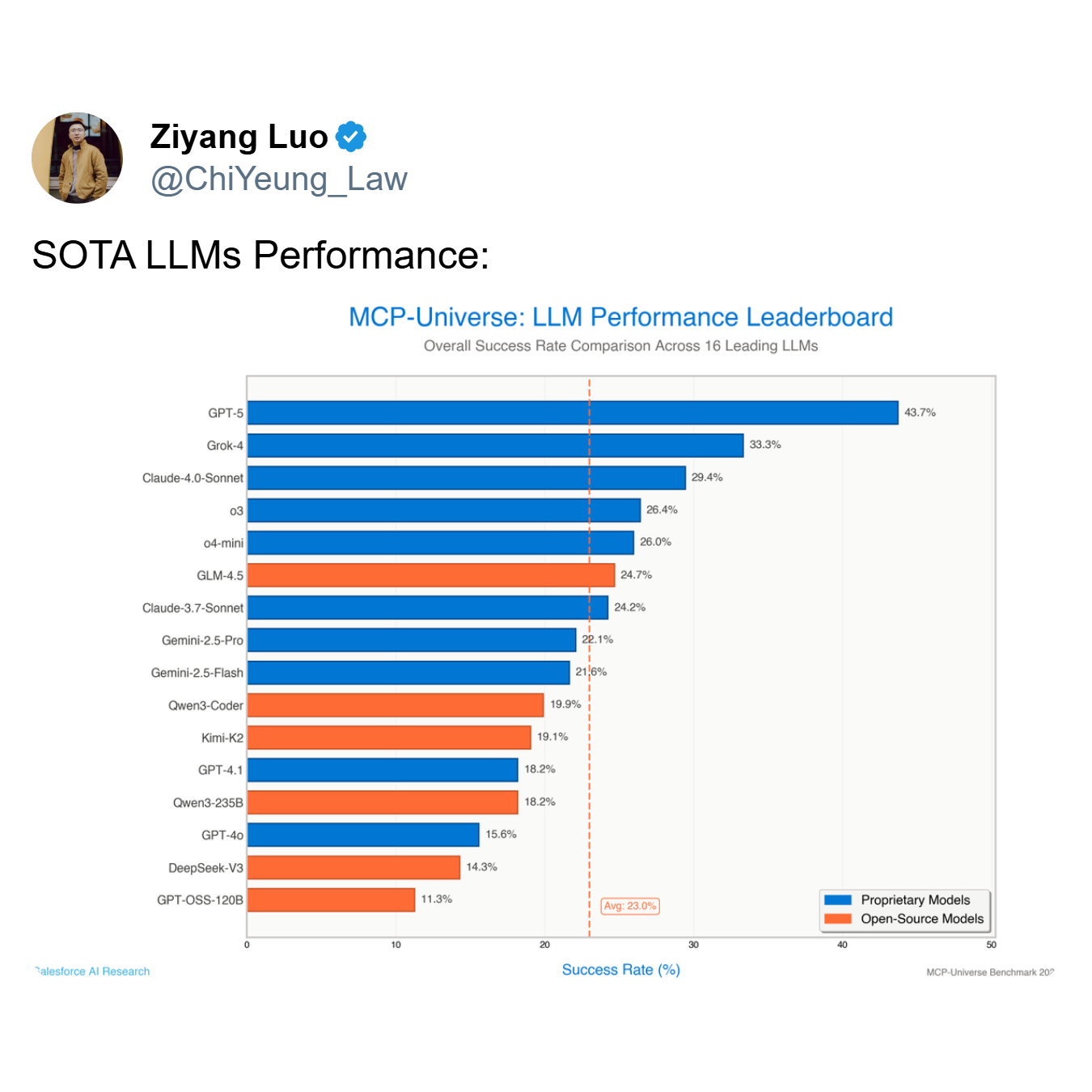
Comme le montre le classement, le modèle le plus performant, GPT-5, atteint un taux de réussite de seulement 43,7%, tandis que la moyenne des 16 principaux modèles chute à un maigre 23,0%. Un agent qui échoue plus de la moitié du temps — comme le font les meilleurs modèles tels que GPT-5 et Grok-4 (33,3% de réussite) — n'est pas un outil utile ; c'est un passif.
Deuxièmement, il y a le problème de l'évolutivité. C'est le défi de maintenir les performances à mesure que le nombre d'outils disponibles passe de dizaines à des centaines, voire des milliers. Un agent peut être modérément fiable avec 5 outils mais s'effondrer complètement lorsqu'on lui en présente 50. Pour une entreprise adoptant le MCP, où le nombre de services intégrés peut croître de manière exponentielle, c'est une préoccupation critique et immédiate. Comme l'a noté Shalev Shalit du Sommet des développeurs MCP, la gestion de cette « surcharge d'outils » est un obstacle majeur pour les organisations qui cherchent à déployer des agents d'IA à grande échelle.
La cause profonde : le défaut architectural des agents monolithiques
Cet échec généralisé n'est pas arbitraire ; il découle de limitations spécifiques et identifiables au sein du paradigme dominant d'un seul agent, un seul modèle. Dans cette architecture, un unique grand modèle de langage (LLM) monolithique est chargé de l'ensemble de la charge de travail cognitive : interpréter l'intention de l'utilisateur, identifier le bon outil, formater l'appel API, exécuter l'action et analyser le résultat. Cette approche est fondamentalement fragile et mal équipée pour la complexité du monde réel, menant directement aux crises de fiabilité et d'évolutivité pour les raisons suivantes :
- Limitation de la fenêtre de contexte : Les LLM ont une fenêtre de contexte finie, qui est la « mémoire de travail » où ils conservent la requête de l'utilisateur, l'historique de la conversation et les schémas des outils disponibles. À mesure que de nouveaux outils sont ajoutés, leurs définitions saturent rapidement cet espace limité, laissant peu de place au processus de raisonnement réel. Le modèle est contraint d'« oublier » ou de négliger des détails critiques, ce qui entraîne des erreurs.
- Surcharge cognitive : Même avec une grande fenêtre de contexte, demander à un seul modèle d'être un expert en tout crée une surcharge cognitive. Le modèle doit simultanément interpréter l'intention, rechercher dans une vaste bibliothèque d'outils, différencier des API subtilement différentes (par exemple,
create_eventvsupdate_event), générer une syntaxe précise et gérer les erreurs. Ce fardeau multitâche dégrade la qualité de sa « pensée » et conduit à de mauvaises prises de décision. - Incapacité à généraliser à des outils inconnus : Les modèles monolithiques ont du mal à utiliser des outils sur lesquels ils n'ont pas été explicitement entraînés. Ils n'ont pas la capacité intrinsèque de comprendre la fonction d'un nouvel outil à partir de son seul schéma, ce qui les amène souvent à halluciner des paramètres, à utiliser l'outil à mauvais escient ou à ne pas l'utiliser du tout.
Un nouveau paradigme de Jenova : résoudre le goulot d'étranglement avec une architecture multi-agents
La solution à ce goulot d'étranglement de l'outillage nécessite un changement architectural fondamental par rapport au modèle monolithique. C'est l'approche pionnière de Jenova, qui s'attaque à ce problème spécifique depuis le début de l'année dernière, bien avant que l'« outillage » ne devienne un concept courant. Jenova a reconnu que la véritable évolutivité et la fiabilité ne pouvaient être atteintes par de simples innovations architecturales ou systémiques. Au lieu de cela, cela nécessitait des années d'expérience et d'accumulation en ingénierie, axées de manière obsessionnelle sur un seul objectif : rendre les architectures multi-agents capables d'utiliser les outils de manière fiable et évolutive.
Ce nouveau paradigme, centré sur un système propriétaire multi-agents, mélange d'experts (MoE), a été conçu pour relever de front les défis de fiabilité et d'évolutivité. Voici une analyse technique de la manière dont l'architecture de Jenova, née d'années d'ingénierie dédiée, résout le problème :
- Routage par Mélange d'Experts (MoE) : Lorsqu'une requête complexe est reçue, le système emploie une couche de routage sophistiquée. Ce routeur classe d'abord l'intention de l'utilisateur dans un domaine spécifique. Par exemple, certains modèles sont hautement spécialisés dans les domaines de recherche d'informations, excellant dans la compréhension des requêtes et l'utilisation d'outils basés sur la recherche. D'autres sont optimisés pour les domaines orientés vers l'action, experts dans l'exécution de tâches telles que la rédaction d'e-mails ou la création d'invitations de calendrier. Une troisième catégorie pourrait se spécialiser dans les domaines analytiques, gérant le traitement des données et le raisonnement logique. La requête est ensuite acheminée vers un agent spécialisé le mieux équipé pour ce domaine spécifique, garantissant que le modèle le plus qualifié gère chaque partie de la tâche.
- Orchestration multi-modèles : Parce que les modèles de différents laboratoires (comme OpenAI, Google et Anthropic) sont entraînés sur des données et des architectures différentes, ils développent des spécialisations distinctes qui s'alignent sur ces domaines. Par exemple, un modèle entraîné de manière intensive sur des données web pourrait être supérieur pour le domaine de la recherche d'informations, tandis qu'un autre modèle affiné pour le suivi d'instructions pourrait exceller dans le domaine orienté vers l'action. Une architecture multi-agents optimale doit avoir la flexibilité de tirer parti de cette diversité, en utilisant le meilleur modèle pour chaque domaine spécifique plutôt que d'être enfermé dans l'écosystème d'une seule entreprise. Le système de Jenova alloue intelligemment le LLM le plus approprié pour chaque tâche, garantissant des performances et une fiabilité optimales à chaque étape du flux de travail.
- Portée contextuelle des outils et chargement juste-à-temps : Pour résoudre la limitation de la fenêtre de contexte et le problème d'évolutivité, l'architecture emploie une approche de chargement d'outils « juste-à-temps ». Plutôt que d'inonder le contexte de l'agent avec tous les outils disponibles, le système utilise des protocoles de routage adaptatifs pour prédire l'ensemble le plus probable d'outils nécessaires pour le graphe de tâches actuel. Seuls les schémas de ce sous-ensemble pertinent sont chargés dans le contexte actif de l'agent, gardant le processus de raisonnement propre et ciblé. Cela réduit considérablement la surcharge de jetons et permet au système de s'adapter à des milliers d'outils potentiels sans dégrader les performances.
L'efficacité de cette approche est validée par les métriques de performance réelles de Jenova. Elle rapporte un taux de réussite d'utilisation des outils de 97,3%. Fait crucial, ce n'est pas un chiffre issu d'un benchmark contrôlé ou d'un environnement de laboratoire affiné. C'est une métrique reflétant les performances en production, à travers un paysage diversifié et non contrôlé de milliers d'utilisateurs interagissant avec une multitude de serveurs et d'outils MCP.
Atteindre ce niveau de fiabilité n'est pas simplement le résultat d'une architecture sophistiquée. La partie la plus difficile de la construction d'un système agentique véritablement évolutif est de s'assurer qu'un nombre infini d'outils divers fonctionne de manière transparente avec différents modèles de différents laboratoires, tous entraînés sur des données différentes. Cela crée une matrice de compatibilité astronomiquement complexe. Résoudre ce problème est analogue à la construction d'un moteur à réaction : avoir le plan est une chose, mais fabriquer un moteur fiable et performant qui fonctionne sous le stress du monde réel nécessite des années d'expertise spécialisée, d'itération et d'une expérience d'ingénierie profonde et composée. Cette robustesse éprouvée en production est ce qui sépare vraiment une conception théorique d'un système fonctionnel de qualité entreprise.
Cette percée a été reconnue par des personnalités clés de la communauté de l'IA. Darren Shepherd, un leader d'opinion et bâtisseur de communauté de premier plan dans l'écosystème MCP, co-fondateur d'Acorn Labs et créateur de la distribution Kubernetes k3s largement utilisée, a observé que cette architecture résout efficacement le problème central.

Conclusion : un impératif architectural pour l'avenir de l'IA agentique
Les données empiriques et les principes architecturaux mènent à une conclusion indéniable : l'avenir des agents d'IA capables, fiables et évolutifs ne peut pas être monolithique. Le paradigme dominant du modèle unique est la cause directe du goulot d'étranglement de l'outillage qui freine actuellement les progrès de l'écosystème MCP et de l'IA agentique dans son ensemble.
Alors que beaucoup dans l'industrie tentent de résoudre ce problème du côté du serveur, cette approche est fondamentalement erronée car elle ne résout pas le problème central de la capacité cognitive limitée de l'agent. La véritable solution doit être centrée sur l'agent. Comme le démontre le succès de Jenova, résoudre ce problème est possible, mais cela nécessite bien plus que la simple amélioration des capacités de base des modèles ou l'ajout d'une couche logique légère. Cela exige un changement de paradigme vers des architectures sophistiquées et centrées sur l'agent, construites sur une expertise approfondie et composée en ingénierie et en architecture, axée spécifiquement sur les défis uniques des systèmes agentiques.