El cuello de botella de las herramientas: cómo los desafíos de fiabilidad y escalabilidad están frenando el futuro de MCP y la IA agéntica
El objetivo de los agentes de IA generales es cambiar fundamentalmente nuestra relación con la tecnología. Imaginamos un futuro en el que la IA no solo proporcione respuestas, sino que actúe como un socio capaz: reservando viajes, gestionando proyectos complejos y orquestando tareas sin problemas en todas las aplicaciones que usamos a diario. El motor que impulsa esta revolución es el "uso de herramientas", donde los agentes de IA se conectan y operan aplicaciones externas a través de API. El Model Context Protocol (MCP), un estándar abierto diseñado para ser el "USB para la IA", ha surgido como el marco "predeterminado" para esta interoperabilidad, creando un lenguaje universal para que agentes y herramientas se comuniquen.
Sin embargo, antes de que los agentes de IA puedan convertirse en una parte fiable de nuestra vida cotidiana, la industria debe superar un cuello de botella grave y urgente: la doble crisis de fiabilidad y escalabilidad de las herramientas.
Desde una perspectiva cotidiana, este problema es simple: si no se puede confiar en que un agente de IA realice una tarea correctamente cada vez, la gente no lo usará. Si le pides a un agente que reserve un vuelo y falla una de cada tres veces, rápidamente volverás a reservarlo tú mismo. Para las corporaciones, lo que está en juego es aún mayor; la falta de fiabilidad es inaceptable para los flujos de trabajo de misión crítica. Además, si un agente solo puede conectarse a un puñado de herramientas antes de que su rendimiento se degrade —el problema de la escalabilidad—, siempre seguirá siendo un dispositivo de nicho, incapaz de manejar los vastos y diversos casos de uso que lo harían verdaderamente transformador. Para que los agentes de IA pasen de ser una novedad a una utilidad indispensable, deben ser tanto fiables como capaces de crecer con nuestras necesidades.
Profundizando en la doble crisis: fiabilidad y escalabilidad
El cuello de botella de las herramientas se manifiesta como dos problemas distintos pero profundamente entrelazados: fiabilidad y escalabilidad. Aunque relacionados, representan diferentes facetas del mismo fallo arquitectónico central.
Primero, está el problema de la fiabilidad: la incapacidad fundamental de un agente para usar herramientas de manera correcta y consistente, incluso con un conjunto limitado. Este es un problema de confianza básica. El benchmark MCP-Universe, un marco integral para evaluar el rendimiento de los agentes, proporciona una cruda evidencia empírica de esta crisis. Pone a prueba a los agentes en tareas complejas de varios pasos que requieren un razonamiento a largo plazo y el uso de conjuntos de herramientas grandes y desconocidos.
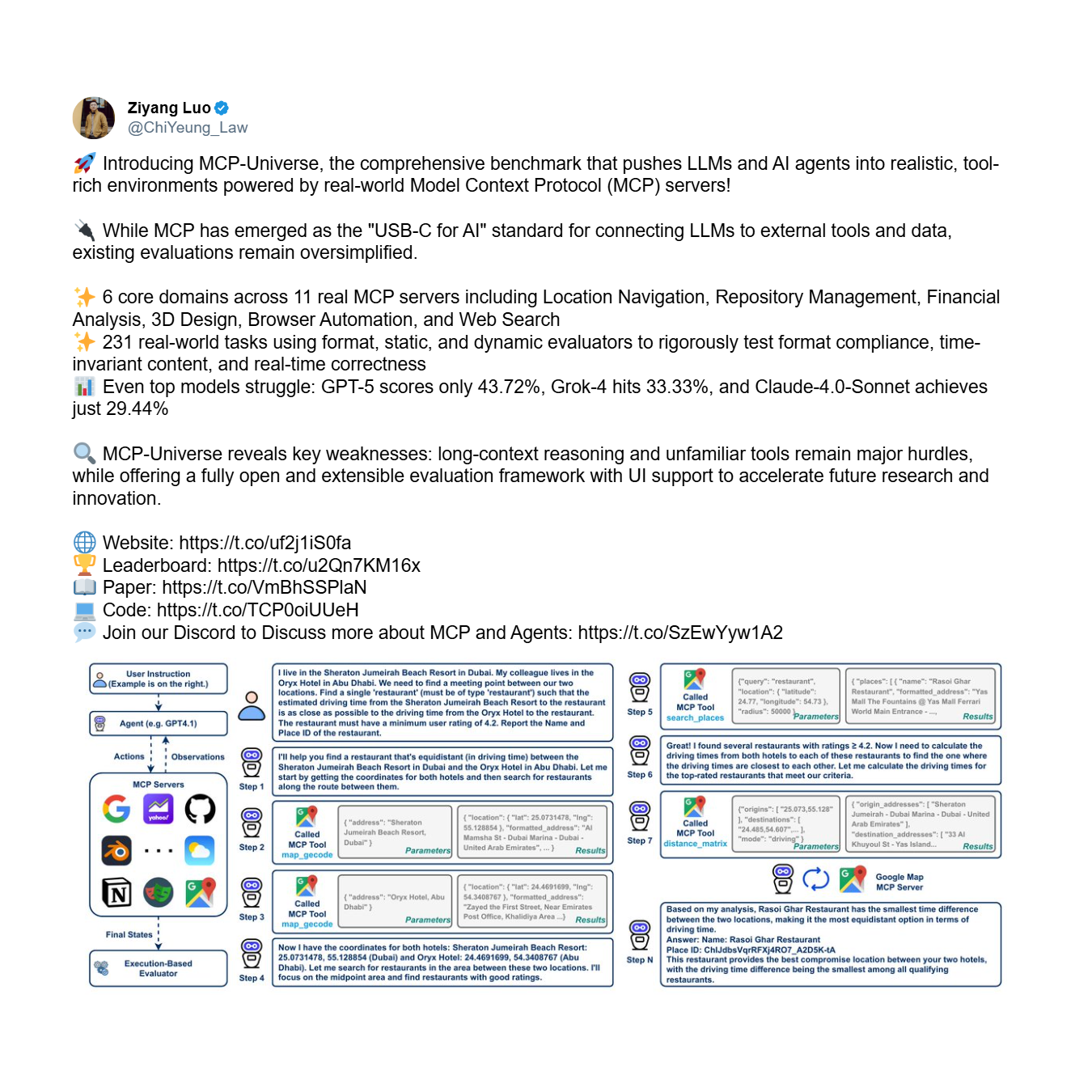
Los resultados son aleccionadores. Incluso los modelos más avanzados fracasan estrepitosamente, exponiendo una incapacidad sistémica para usar herramientas de manera fiable.
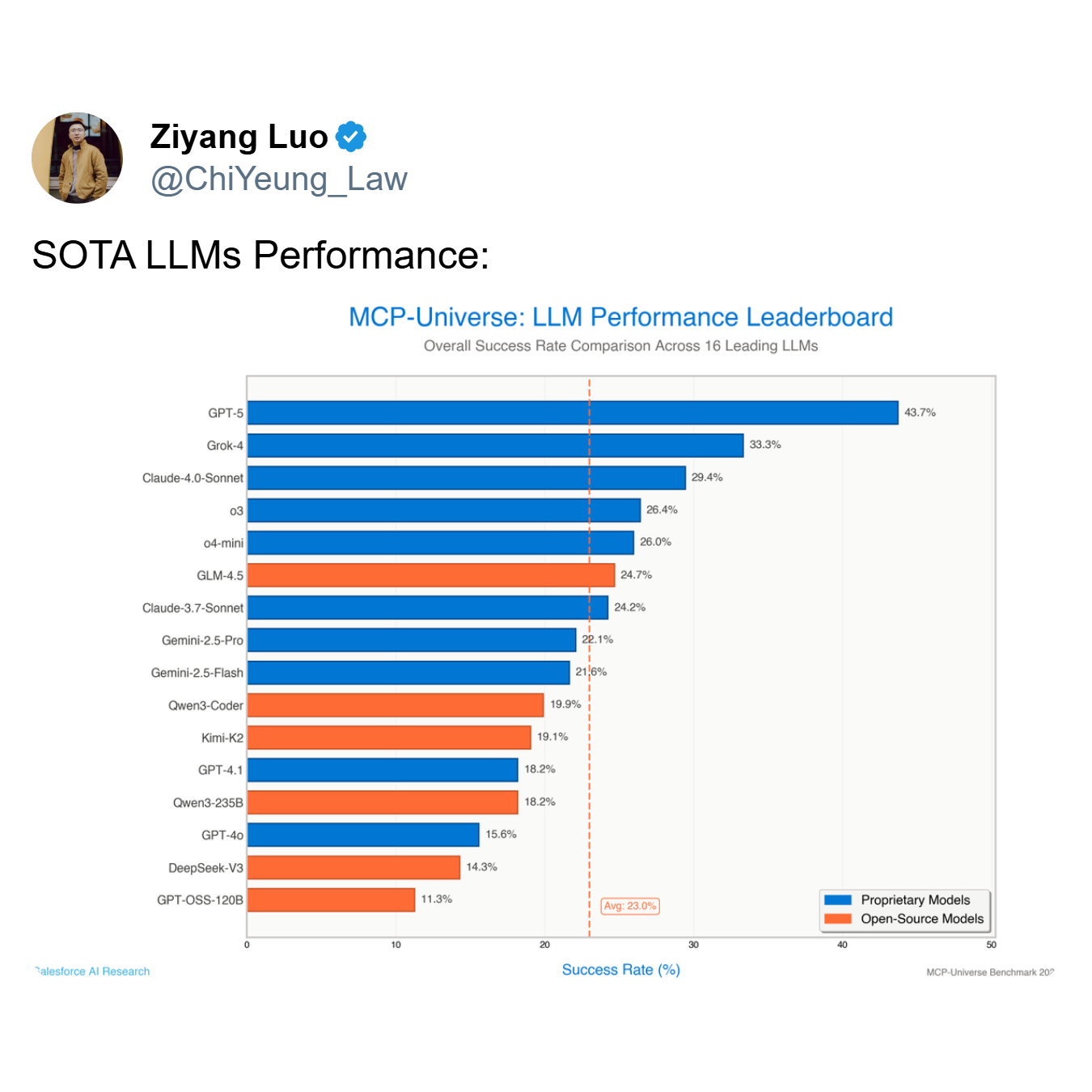
Como demuestra la tabla de clasificación, el modelo con mejor rendimiento, GPT-5, alcanza una tasa de éxito de solo el 43,7%, mientras que el promedio de los 16 modelos principales se desploma a un mero 23,0%. Un agente que falla más de la mitad de las veces —como lo hacen los modelos de primer nivel como GPT-5 y Grok-4 (33,3% de éxito)— no es una herramienta útil; es un riesgo.
Segundo, está el problema de la escalabilidad. Este es el desafío de mantener el rendimiento a medida que el número de herramientas disponibles se expande de decenas a cientos o incluso miles. Un agente puede ser moderadamente fiable con 5 herramientas, pero colapsar por completo cuando se le presentan 50. Para una empresa que adopta MCP, donde el número de servicios integrados puede crecer exponencialmente, esta es una preocupación crítica e inmediata. Como señaló Shalev Shalit de la Cumbre de Desarrolladores de MCP, gestionar esta "sobrecarga de herramientas" es un obstáculo principal para las organizaciones que buscan desplegar agentes de IA a escala.
La causa raíz: el fallo arquitectónico de los agentes monolíticos
Este fracaso generalizado no es arbitrario; se deriva de limitaciones específicas e identificables dentro del paradigma dominante de un solo agente, un solo modelo. En esta arquitectura, un único Modelo de Lenguaje Grande (LLM) monolítico se encarga de toda la carga cognitiva: interpretar la intención del usuario, identificar la herramienta correcta, formatear la llamada a la API, ejecutar la acción y analizar el resultado. Este enfoque es fundamentalmente frágil y está mal equipado para la complejidad del mundo real, lo que conduce directamente a las crisis de fiabilidad y escalabilidad por las siguientes razones:
- Limitación de la ventana de contexto: Los LLM tienen una ventana de contexto finita, que es la "memoria de trabajo" donde guardan la consulta del usuario, el historial de la conversación y los esquemas de las herramientas disponibles. A medida que se agregan más herramientas, sus definiciones saturan rápidamente este espacio limitado, dejando poco espacio para el proceso de razonamiento real. El modelo se ve obligado a "olvidar" o pasar por alto detalles críticos, lo que conduce a errores.
- Sobrecarga cognitiva: Incluso con una ventana de contexto grande, pedirle a un solo modelo que sea un experto en todo crea una sobrecarga cognitiva. El modelo debe interpretar simultáneamente la intención, buscar en una vasta biblioteca de herramientas, diferenciar entre API sutilmente diferentes (p. ej.,
create_eventvs.update_event), generar una sintaxis precisa y manejar errores. Esta carga multitarea degrada la calidad de su "pensamiento" y conduce a una mala toma de decisiones. - Incapacidad para generalizar a herramientas no vistas: Los modelos monolíticos tienen dificultades para usar herramientas para las que no han sido entrenados explícitamente. Carecen de la capacidad intrínseca para comprender la función de una nueva herramienta solo a partir de su esquema, lo que a menudo los lleva a alucinar parámetros, usar la herramienta para el propósito equivocado o no usarla en absoluto.
Un nuevo paradigma de Jenova: resolviendo el cuello de botella con una arquitectura multiagente
La solución a este cuello de botella de las herramientas requiere un cambio arquitectónico fundamental que se aleje del modelo monolítico. Este es el enfoque pionero de Jenova, que ha estado abordando este problema específico desde principios del año pasado, mucho antes de que el "tooling" se convirtiera en un concepto generalizado. Jenova reconoció que la verdadera escalabilidad y fiabilidad no se podían lograr solo a través de simples innovaciones arquitectónicas o de sistema. En cambio, requería años de experiencia e acumulación de ingeniería compuesta, enfocada obsesivamente en un único objetivo: hacer que las arquitecturas multiagente usen herramientas de manera fiable y escalable.
Este nuevo paradigma, centrado en un sistema propietario de multiagente, mezcla de expertos (MoE), fue diseñado para abordar de frente tanto los desafíos de fiabilidad como de escalabilidad. Aquí hay un desglose técnico de cómo la arquitectura de Jenova, nacida de años de ingeniería dedicada, resuelve el problema:
- Enrutamiento de Mezcla de Expertos (MoE): Cuando se recibe una solicitud compleja, el sistema emplea una capa de enrutamiento sofisticada. Este enrutador primero clasifica la intención del usuario en un dominio específico. Por ejemplo, algunos modelos están altamente especializados en dominios de recuperación de información, destacando en la comprensión de consultas y el uso de herramientas basadas en búsqueda. Otros están optimizados para dominios orientados a la acción, expertos en ejecutar tareas como redactar correos electrónicos o crear invitaciones de calendario. Una tercera categoría podría especializarse en dominios analíticos, manejando el procesamiento de datos y el razonamiento lógico. La solicitud se enruta luego a un agente especializado mejor equipado para ese dominio específico, asegurando que el modelo más calificado maneje cada parte de la tarea.
- Orquestación multimodelo: Debido a que los modelos de diferentes laboratorios (como OpenAI, Google y Anthropic) se entrenan con diferentes datos y arquitecturas, desarrollan especializaciones distintas que se alinean con estos dominios. Por ejemplo, un modelo entrenado extensamente en datos web podría ser superior para el dominio de recuperación de información, mientras que otro modelo afinado para seguir instrucciones podría sobresalir en el dominio orientado a la acción. Una arquitectura multiagente óptima debe tener la flexibilidad para aprovechar esta diversidad, utilizando el mejor modelo para cada dominio específico en lugar de estar encerrado en el ecosistema de una sola empresa. El sistema de Jenova asigna inteligentemente el LLM más apropiado para cada trabajo, asegurando el máximo rendimiento y fiabilidad en cada etapa del flujo de trabajo.
- Alcance contextual de herramientas y carga justo a tiempo: Para resolver la limitación de la ventana de contexto y el problema de escalabilidad, la arquitectura emplea un enfoque de carga de herramientas "justo a tiempo". En lugar de inundar el contexto del agente con todas las herramientas disponibles, el sistema utiliza protocolos de enrutamiento adaptativo para predecir el conjunto más probable de herramientas necesarias para el gráfico de tareas actual. Solo los esquemas de este subconjunto relevante se cargan en el contexto activo del agente, manteniendo el proceso de razonamiento limpio y enfocado. Esto reduce drásticamente la sobrecarga de tokens y permite que el sistema escale a miles de herramientas potenciales sin degradar el rendimiento.
La eficacia de este enfoque está validada por las métricas de rendimiento del mundo real de Jenova. Reporta una tasa de éxito en el uso de herramientas del 97,3%. Críticamente, esta no es una cifra de un benchmark controlado o un entorno de laboratorio afinado. Es una métrica que refleja el rendimiento en producción, en un panorama diverso y no controlado de miles de usuarios que interactúan con una multitud de servidores y herramientas de MCP.
Lograr este nivel de fiabilidad no es simplemente el resultado de una arquitectura sofisticada. La parte más difícil de construir un sistema agéntico verdaderamente escalable es garantizar que un número infinito de herramientas diversas funcionen sin problemas con diferentes modelos de diferentes laboratorios, todos los cuales están entrenados con datos diferentes. Esto crea una matriz de compatibilidad astronómicamente compleja. Resolver esto es análogo a construir un motor a reacción: tener el plano es una cosa, pero fabricar un motor fiable y de alto rendimiento que funcione bajo el estrés del mundo real requiere años de experiencia especializada, iteración y una profunda experiencia de ingeniería compuesta. Esta robustez endurecida en producción es lo que realmente separa un diseño teórico de un sistema funcional de nivel empresarial.
Este avance ha sido reconocido por figuras clave en la comunidad de IA. Darren Shepherd, un destacado líder de opinión y constructor de comunidades en el ecosistema de MCP, cofundador de Acorn Labs y creador de la ampliamente utilizada distribución de Kubernetes k3s, observó que esta arquitectura resuelve eficazmente el problema central.

Conclusión: un imperativo arquitectónico para el futuro de la IA agéntica
Los datos empíricos y los principios arquitectónicos conducen a una conclusión innegable: el futuro de los agentes de IA capaces, fiables y escalables no puede ser monolítico. El paradigma predominante de un solo modelo es la causa directa del cuello de botella de las herramientas que actualmente frena el progreso del ecosistema de MCP y de la IA agéntica en su conjunto.
Aunque muchos en la industria intentan abordar esto desde el lado del servidor, este enfoque es fundamentalmente erróneo ya que no resuelve el problema central de la capacidad cognitiva limitada del agente. La verdadera solución debe estar centrada en el agente. Como demuestra el éxito de Jenova, resolver este problema es posible, pero requiere mucho más que simplemente mejorar las capacidades base de los modelos o agregar una capa lógica ligera. Exige un cambio de paradigma hacia arquitecturas sofisticadas y centradas en el agente, construidas sobre una profunda experiencia de ingeniería y arquitectura compuesta, enfocada específicamente en los desafíos únicos de los sistemas agénticos.