The Tooling Bottleneck: How Reliability and Scalability Challenges Are Stalling the Future of MCP and Agentic AI
The goal of general AI agents is to fundamentally change our relationship with technology. We envision a future where AI doesn't just provide answers, but acts as a capable partner—booking travel, managing complex projects, and seamlessly orchestrating tasks across all the apps we use daily. The engine driving this revolution is "tool use," where AI agents connect to and operate external applications via APIs. The Model Context Protocol (MCP), an open standard designed to be the "USB for AI," has emerged as the "default" framework for this interoperability, creating a universal language for agents and tools to communicate.
However, before AI agents can become a reliable part of our everyday lives, the industry must overcome a severe and urgent bottleneck: the dual crisis of tool reliability and scalability.
From an everyday perspective, this problem is simple: if an AI agent can't be trusted to perform a task correctly every single time, people won't use it. If you ask an agent to book a flight and it fails one out of three times, you'll quickly go back to booking it yourself. For corporations, the stakes are even higher; unreliability is a non-starter for mission-critical workflows. Furthermore, if an agent can only connect to a handful of tools before its performance degrades—the scalability problem—it will forever remain a niche gadget, unable to handle the vast and diverse use cases that would make it truly transformative. For AI agents to move from a novelty to an indispensable utility, they must be both dependable and capable of growing with our needs.
Diving into the Twin Crises: Reliability and Scalability
The tooling bottleneck manifests as two distinct but deeply intertwined problems: reliability and scalability. While related, they represent different facets of the same core architectural failure.
First, there is the reliability problem: the fundamental inability of an agent to use tools correctly and consistently, even with a limited set. This is an issue of basic trustworthiness. The MCP-Universe benchmark, a comprehensive framework for evaluating agent performance, provides stark empirical evidence of this crisis. It tests agents on complex, multi-step tasks requiring long-horizon reasoning and the use of large, unfamiliar toolsets.
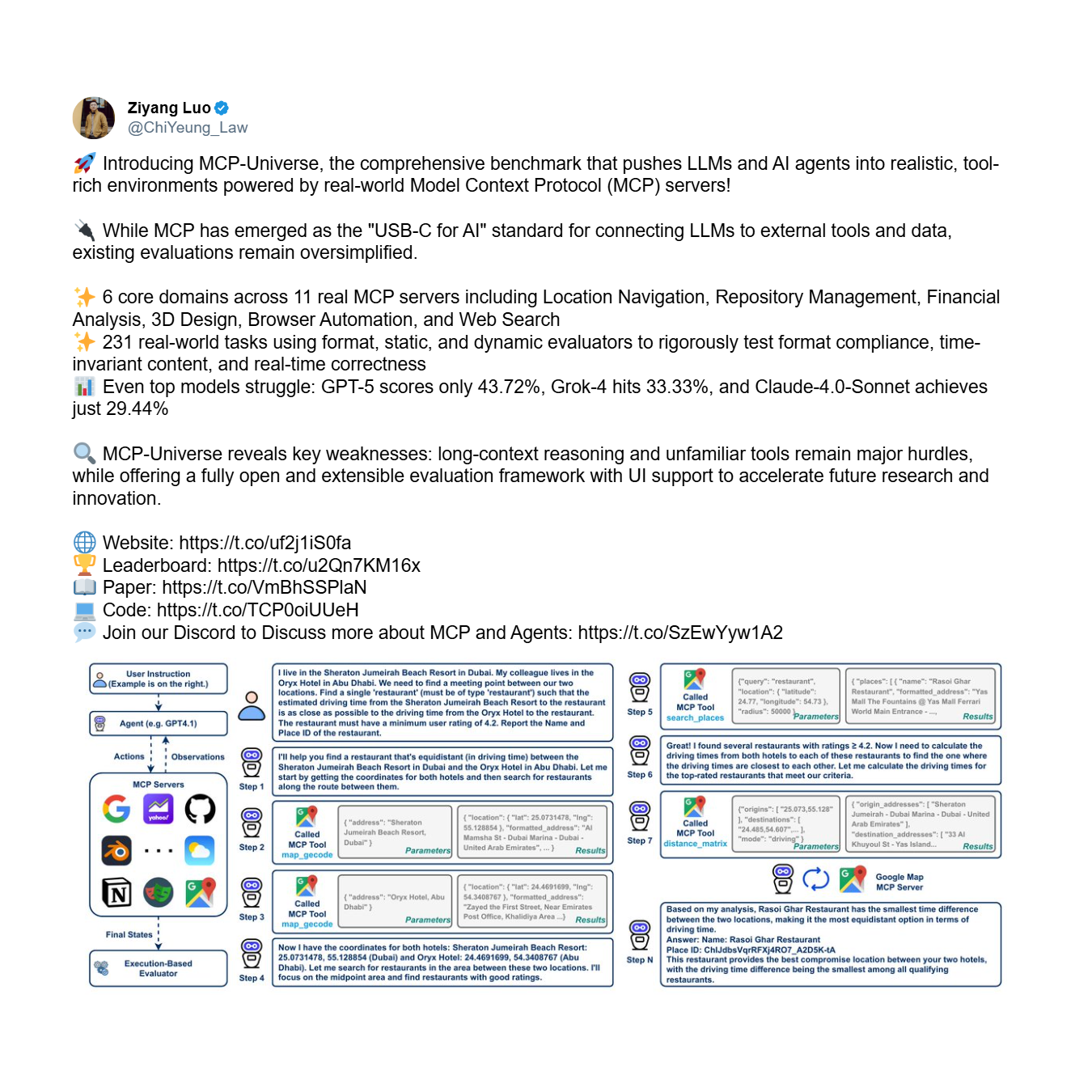
The results are sobering. Even the most advanced models fail spectacularly, exposing a systemic inability to reliably use tools.
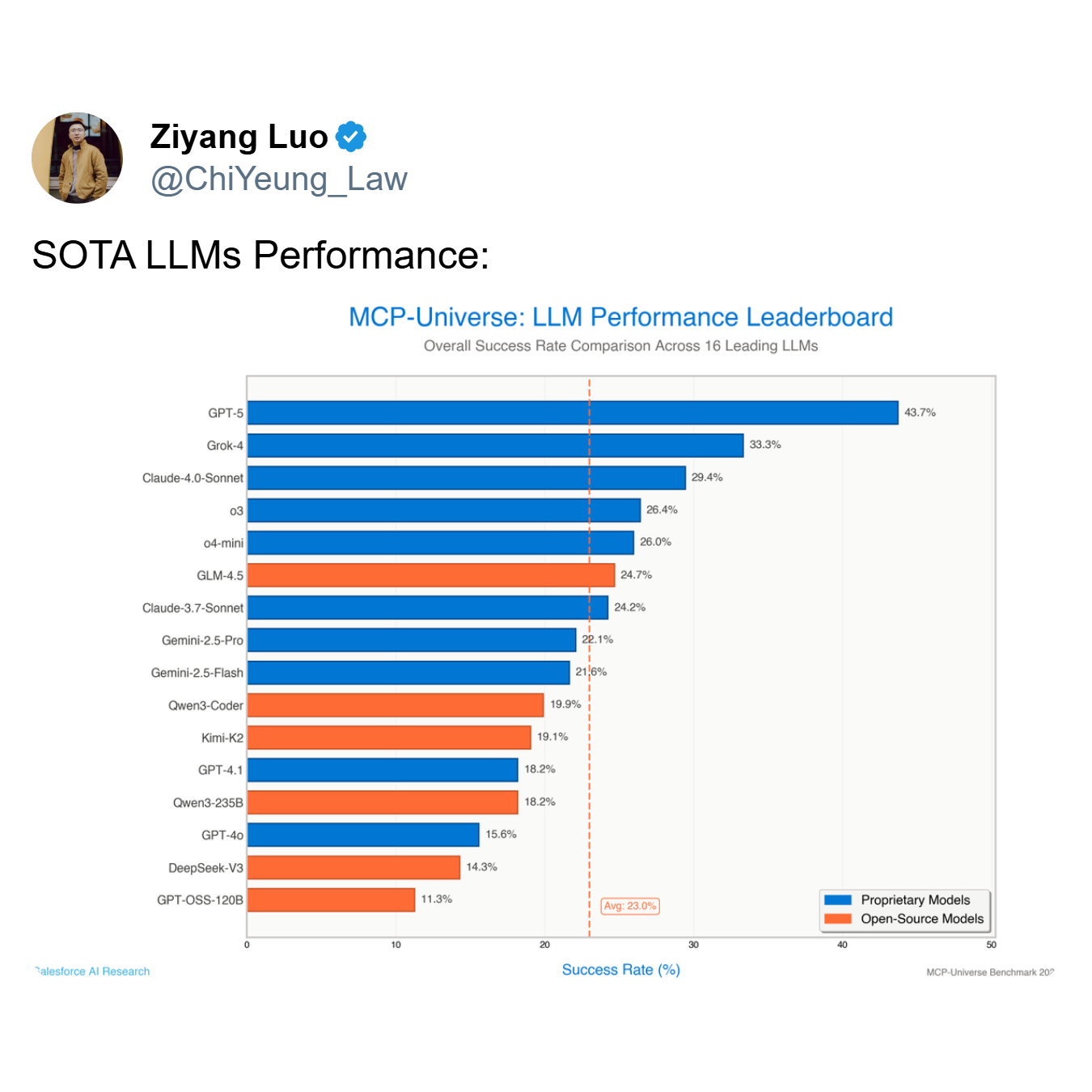
As the leaderboard demonstrates, the top-performing model, GPT-5, achieves a success rate of only 43.7%, while the average across all 16 leading models plummets to a mere 23.0%. An agent that fails more than half the time—as top models like GPT-5 and Grok-4 (33.3% success) do—is not a useful tool; it's a liability.
Second, there is the scalability problem. This is the challenge of maintaining performance as the number of available tools expands from tens to hundreds or even thousands. An agent might be moderately reliable with 5 tools but completely collapse when presented with 50. For an enterprise adopting MCP, where the number of integrated services can grow exponentially, this is a critical and immediate concern. As noted by Shalev Shalit of the MCP Developers Summit, managing this "tool overload" is a primary obstacle for organizations aiming to deploy AI agents at scale.
The Root Cause: The Architectural Flaw of Monolithic Agents
This widespread failure is not arbitrary; it stems from specific, identifiable limitations within the dominant single-agent, single-model paradigm. In this architecture, one monolithic Large Language Model (LLM) is tasked with the entire cognitive workload: interpreting user intent, identifying the correct tool, formatting the API call, executing the action, and parsing the result. This approach is fundamentally brittle and ill-equipped for real-world complexity, leading directly to the reliability and scalability crises for the following reasons:
- Context Window Limitation: LLMs have a finite context window, which is the "working memory" where they hold the user's query, conversation history, and the schemas of available tools. As more tools are added, their definitions quickly saturate this limited space, leaving little room for the actual reasoning process. The model is forced to "forget" or overlook critical details, leading to errors.
- Cognitive Overload: Even with a large context window, asking a single model to be an expert at everything creates cognitive overload. The model must simultaneously interpret intent, search a vast library of tools, differentiate between subtly different APIs (e.g.,
create_eventvs.update_event), generate precise syntax, and handle errors. This multi-tasking burden degrades the quality of its "thinking" and leads to poor decision-making. - Inability to Generalize to Unseen Tools: Monolithic models struggle to use tools they haven't been explicitly trained on. They lack the intrinsic ability to understand a new tool's function from its schema alone, often leading them to hallucinate parameters, use the tool for the wrong purpose, or fail to use it at all.
A New Paradigm from Jenova: Solving the Bottleneck with a Multi-Agent Architecture
The solution to this tooling bottleneck requires a fundamental architectural shift away from the monolithic model. This is the approach pioneered by Jenova, which has been tackling this specific problem since early last year, long before "tooling" became a mainstream concept. Jenova recognized that true scalability and reliability could not be achieved through simple architectural or system innovations alone. Instead, it required years of compounded engineering experience and accumulation, focused obsessively on a single goal: making multi-agent architectures use tools reliably and scalably.
This new paradigm, centered on a proprietary multi-agent, mixture-of-experts (MoE) system, was engineered to address both the reliability and scalability challenges head-on. Here is a technical breakdown of how Jenova's architecture, born from years of dedicated engineering, solves the problem:
- Mixture-of-Experts (MoE) Routing: When a complex request is received, the system employs a sophisticated routing layer. This router first classifies the user's intent into a specific domain. For example, some models are highly specialized for information-retrieval domains, excelling at understanding queries and using search-based tools. Others are optimized for action-oriented domains, adept at executing tasks like drafting emails or creating calendar invites. A third category might specialize in analytical domains, handling data processing and logical reasoning. The request is then routed to a specialized agent best equipped for that specific domain, ensuring the most qualified model handles each part of the task.
- Multi-Model Orchestration: Because models from different labs (like OpenAI, Google, and Anthropic) are trained on different data and architectures, they develop distinct specializations that align with these domains. For instance, a model trained extensively on web data might be superior for the information-retrieval domain, while another model fine-tuned for instruction-following might excel in the action-oriented domain. An optimal multi-agent architecture must have the flexibility to leverage this diversity, using the best model for each specific domain rather than being locked into a single company's ecosystem. Jenova's system intelligently allocates the most appropriate LLM for each job, ensuring peak performance and reliability at every stage of the workflow.
- Contextual Tool Scoping and Just-in-Time Loading: To solve the context window limitation and scalability problem, the architecture employs a "just-in-time" approach to tool loading. Rather than flooding the agent's context with every available tool, the system uses adaptive routing protocols to predict the most probable set of tools needed for the current task graph. Only the schemas for this relevant subset are loaded into the agent's active context, keeping the reasoning process clean and focused. This dramatically reduces token overhead and allows the system to scale to thousands of potential tools without degrading performance.
The efficacy of this approach is validated by Jenova's real-world performance metrics. It reports a 97.3% tool-use success rate. Critically, this is not a figure from a controlled benchmark or a fine-tuned lab environment. It is a metric reflecting performance in production, across a diverse and uncontrolled landscape of thousands of users interacting with a multitude of MCP servers and tools.
Achieving this level of reliability is not merely the result of a sophisticated architecture. The hardest part of building a truly scalable agentic system is ensuring that an infinite number of diverse tools work seamlessly with different models from different labs, all of which are trained on different data. This creates an astronomically complex compatibility matrix. Solving this is analogous to building a jet engine: having the blueprint is one thing, but manufacturing a reliable, high-performance engine that works under real-world stress requires years of specialized expertise, iteration, and deep, compounded engineering experience. This production-hardened robustness is what truly separates a theoretical design from a functional, enterprise-grade system.
This breakthrough has been recognized by key figures in the AI community. Darren Shepherd, a prominent thought leader and community builder in the MCP ecosystem, co-founder of Acorn Labs, and creator of the widely-used k3s Kubernetes distribution, observed that this architecture effectively solves the core issue.

Conclusion: An Architectural Imperative for the Future of Agentic AI
The empirical data and architectural principles lead to an undeniable conclusion: the future of capable, reliable, and scalable AI agents cannot be monolithic. The prevailing single-model paradigm is the direct cause of the tooling bottleneck that currently stalls the progress of the MCP ecosystem and agentic AI as a whole.
While many in the industry attempt to address this from the server side, this approach is fundamentally misguided as it fails to solve the core issue of the agent's limited cognitive capacity. The true solution must be agent-centric. As Jenova's success demonstrates, solving this problem is possible, but it requires far more than simply improving the base capabilities of models or adding a light logic layer. It demands a paradigm shift towards sophisticated, agent-centric architectures built on deep, compounded engineering and architectural expertise focused specifically on the unique challenges of agentic systems.