Der Tooling-Engpass: Wie Zuverlässigkeits- und Skalierbarkeitsherausforderungen die Zukunft von MCP und agentenbasierter KI blockieren
Das Ziel allgemeiner KI-Agenten ist es, unsere Beziehung zur Technologie grundlegend zu verändern. Wir stellen uns eine Zukunft vor, in der KI nicht nur Antworten liefert, sondern als fähiger Partner agiert – Reisen bucht, komplexe Projekte verwaltet und nahtlos Aufgaben über alle von uns täglich genutzten Apps hinweg orchestriert. Der Motor dieser Revolution ist die „Tool-Nutzung“, bei der KI-Agenten über APIs mit externen Anwendungen verbunden sind und diese bedienen. Das Model Context Protocol (MCP), ein offener Standard, der als „USB für KI“ konzipiert wurde, hat sich als „Standard“-Framework für diese Interoperabilität etabliert und schafft eine universelle Sprache für die Kommunikation zwischen Agenten und Tools.
Bevor KI-Agenten jedoch zu einem zuverlässigen Teil unseres Alltags werden können, muss die Branche einen schwerwiegenden und dringenden Engpass überwinden: die doppelte Krise der Zuverlässigkeit und Skalierbarkeit von Tools.
Aus alltäglicher Sicht ist dieses Problem einfach: Wenn man einem KI-Agenten nicht zutrauen kann, eine Aufgabe jedes Mal korrekt auszuführen, werden die Leute ihn nicht benutzen. Wenn Sie einen Agenten bitten, einen Flug zu buchen, und er bei einem von drei Versuchen scheitert, werden Sie schnell wieder selbst buchen. Für Unternehmen steht noch mehr auf dem Spiel; Unzuverlässigkeit ist für geschäftskritische Arbeitsabläufe ein K.o.-Kriterium. Wenn ein Agent außerdem nur eine Handvoll Tools verbinden kann, bevor seine Leistung nachlässt – das Skalierbarkeitsproblem –, wird er für immer ein Nischen-Gadget bleiben, das nicht in der Lage ist, die riesigen und vielfältigen Anwendungsfälle zu bewältigen, die es wirklich transformativ machen würden. Damit KI-Agenten von einer Neuheit zu einem unverzichtbaren Werkzeug werden, müssen sie sowohl zuverlässig als auch in der Lage sein, mit unseren Bedürfnissen zu wachsen.
Einblicke in die Zwillingskrisen: Zuverlässigkeit und Skalierbarkeit
Der Tooling-Engpass manifestiert sich in zwei unterschiedlichen, aber tief miteinander verknüpften Problemen: Zuverlässigkeit und Skalierbarkeit. Obwohl sie miteinander verbunden sind, repräsentieren sie unterschiedliche Facetten desselben architektonischen Kernfehlers.
Erstens gibt es das Zuverlässigkeitsproblem: die grundlegende Unfähigkeit eines Agenten, Tools korrekt und konsistent zu verwenden, selbst mit einem begrenzten Satz. Dies ist eine Frage der grundlegenden Vertrauenswürdigkeit. Der MCP-Universe Benchmark, ein umfassendes Framework zur Bewertung der Agentenleistung, liefert deutliche empirische Beweise für diese Krise. Er testet Agenten bei komplexen, mehrstufigen Aufgaben, die weitreichendes Denken und die Verwendung großer, unbekannter Toolsets erfordern.
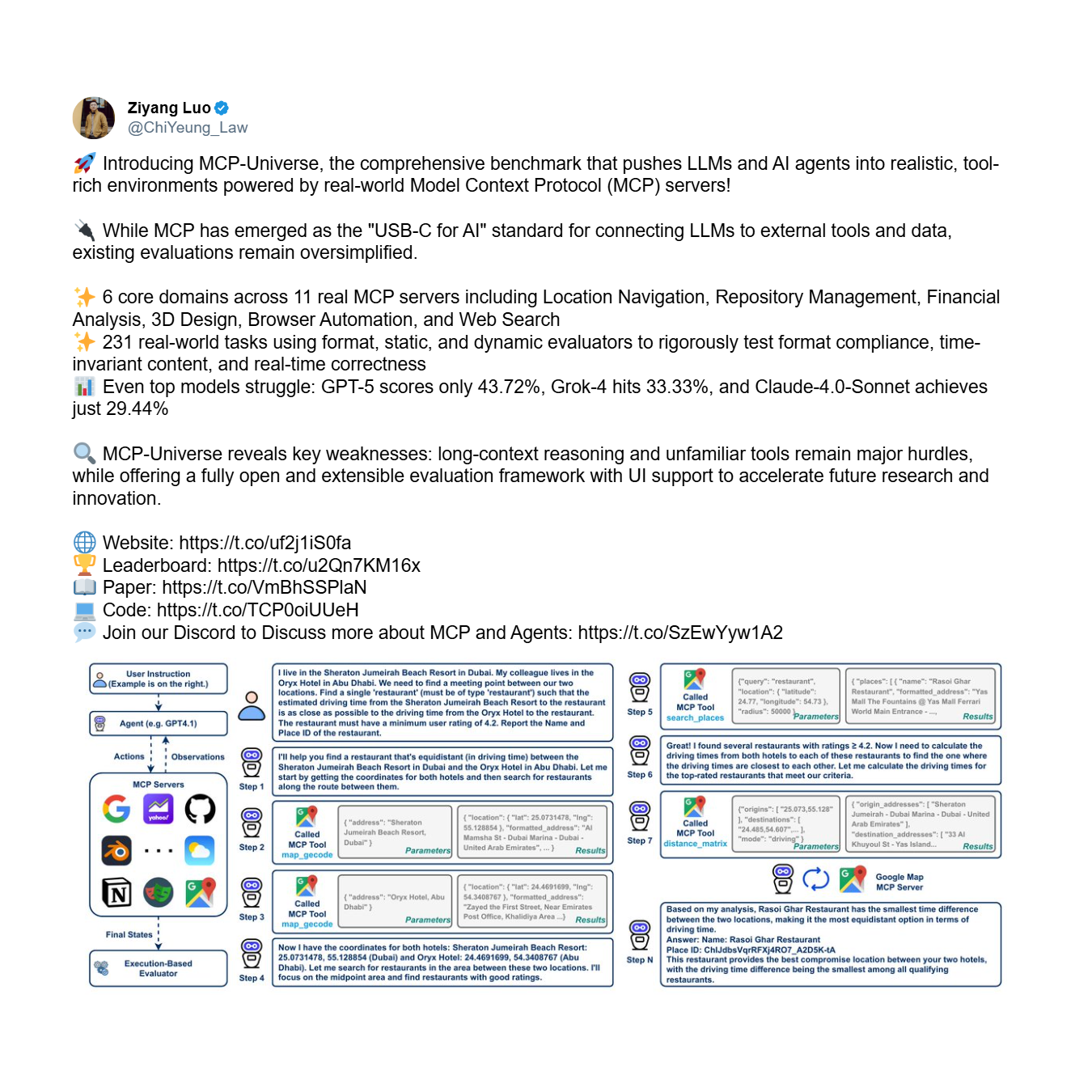
Die Ergebnisse sind ernüchternd. Selbst die fortschrittlichsten Modelle scheitern spektakulär und offenbaren eine systemische Unfähigkeit, Tools zuverlässig zu nutzen.
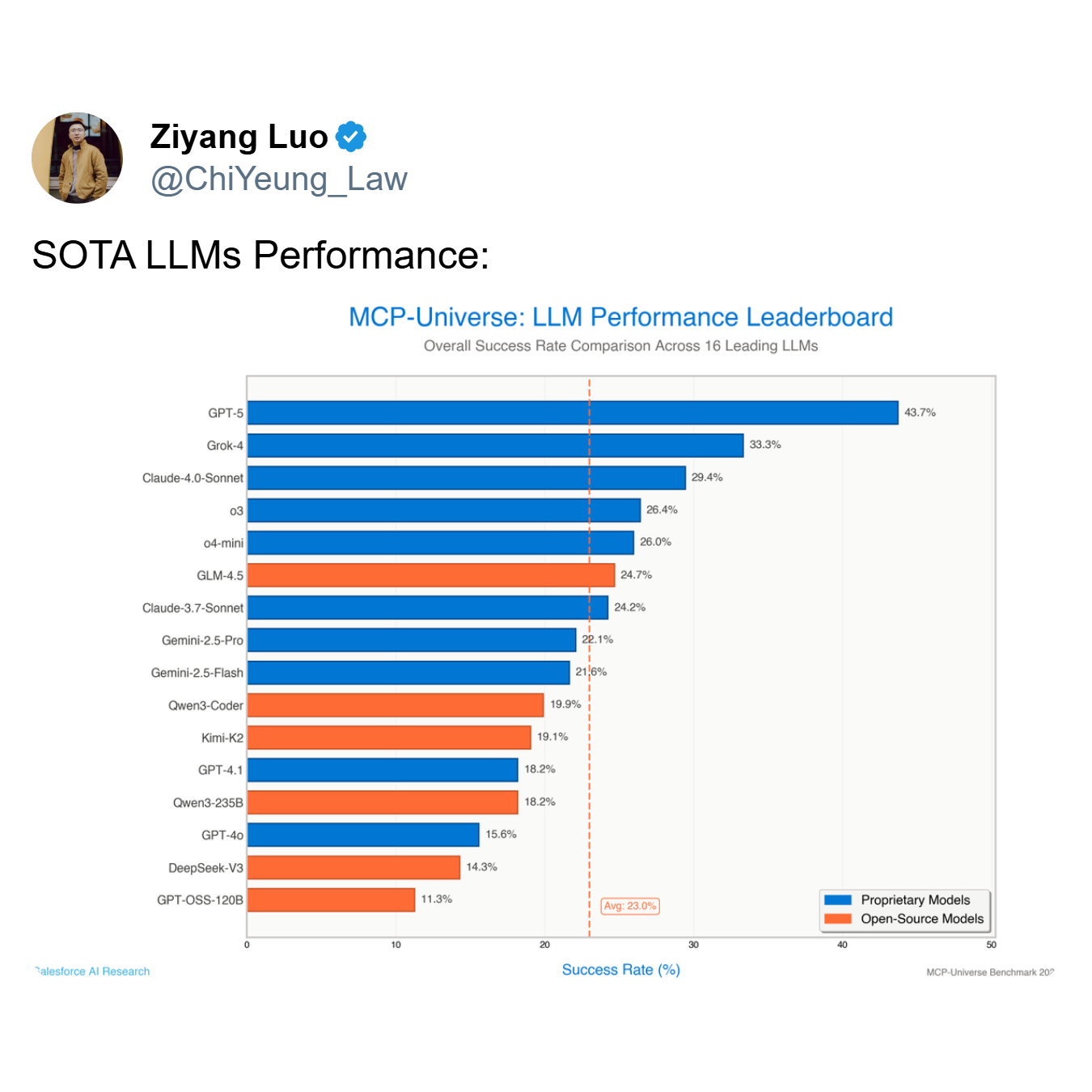
Wie die Rangliste zeigt, erreicht das leistungsstärkste Modell, GPT-5, eine Erfolgsquote von nur 43,7%, während der Durchschnitt aller 16 führenden Modelle auf magere 23,0% abstürzt. Ein Agent, der mehr als die Hälfte der Zeit versagt – wie es bei Top-Modellen wie GPT-5 und Grok-4 (33,3% Erfolg) der Fall ist – ist kein nützliches Werkzeug; er ist ein Haftungsrisiko.
Zweitens gibt es das Skalierbarkeitsproblem. Dies ist die Herausforderung, die Leistung aufrechtzuerhalten, wenn die Anzahl der verfügbaren Tools von zehn auf Hunderte oder sogar Tausende anwächst. Ein Agent mag mit 5 Tools mäßig zuverlässig sein, aber bei 50 Tools komplett zusammenbrechen. Für ein Unternehmen, das MCP einführt, wo die Anzahl der integrierten Dienste exponentiell wachsen kann, ist dies ein kritisches und unmittelbares Anliegen. Wie Shalev Shalit vom MCP Developers Summit anmerkte, ist die Bewältigung dieser „Tool-Überlastung“ ein Haupthindernis für Organisationen, die KI-Agenten in großem Maßstab einsetzen wollen.
Die Wurzel des Problems: Der architektonische Fehler monolithischer Agenten
Dieses weit verbreitete Versagen ist nicht willkürlich; es resultiert aus spezifischen, identifizierbaren Einschränkungen innerhalb des dominanten Single-Agent-, Single-Model-Paradigmas. In dieser Architektur wird ein monolithisches Large Language Model (LLM) mit der gesamten kognitiven Arbeitslast betraut: Interpretation der Benutzerabsicht, Identifizierung des richtigen Tools, Formatierung des API-Aufrufs, Ausführung der Aktion und Analyse des Ergebnisses. Dieser Ansatz ist grundlegend spröde und für die Komplexität der realen Welt schlecht gerüstet, was direkt zu den Zuverlässigkeits- und Skalierbarkeitskrisen aus folgenden Gründen führt:
- Begrenzung des Kontextfensters: LLMs haben ein endliches Kontextfenster, das der „Arbeitsspeicher“ ist, in dem sie die Anfrage des Benutzers, den Gesprächsverlauf und die Schemata der verfügbaren Tools speichern. Wenn mehr Tools hinzugefügt werden, füllen deren Definitionen diesen begrenzten Raum schnell aus und lassen wenig Platz für den eigentlichen Denkprozess. Das Modell ist gezwungen, kritische Details zu „vergessen“ oder zu übersehen, was zu Fehlern führt.
- Kognitive Überlastung: Selbst mit einem großen Kontextfenster führt die Anforderung an ein einzelnes Modell, ein Experte für alles zu sein, zu kognitiver Überlastung. Das Modell muss gleichzeitig die Absicht interpretieren, eine riesige Bibliothek von Tools durchsuchen, zwischen subtil unterschiedlichen APIs unterscheiden (z. B.
create_eventvs.update_event), präzise Syntax generieren und Fehler behandeln. Diese Multitasking-Belastung beeinträchtigt die Qualität seines „Denkens“ und führt zu schlechten Entscheidungen. - Unfähigkeit, auf unbekannte Tools zu generalisieren: Monolithische Modelle haben Schwierigkeiten, Tools zu verwenden, für die sie nicht explizit trainiert wurden. Ihnen fehlt die intrinsische Fähigkeit, die Funktion eines neuen Tools allein aus seinem Schema zu verstehen, was sie oft dazu verleitet, Parameter zu halluzinieren, das Tool für den falschen Zweck zu verwenden oder es gar nicht zu verwenden.
Ein neues Paradigma von Jenova: Lösung des Engpasses mit einer Multi-Agenten-Architektur
Die Lösung für diesen Tooling-Engpass erfordert einen grundlegenden architektonischen Wandel weg vom monolithischen Modell. Dies ist der von Jenova vorangetriebene Ansatz, der sich seit Anfang letzten Jahres mit diesem spezifischen Problem befasst, lange bevor „Tooling“ zu einem Mainstream-Konzept wurde. Jenova erkannte, dass wahre Skalierbarkeit und Zuverlässigkeit nicht allein durch einfache architektonische oder systemische Innovationen erreicht werden konnten. Stattdessen erforderte es Jahre gebündelter Ingenieurserfahrung und -akkumulation, die sich zwanghaft auf ein einziges Ziel konzentrierte: Multi-Agenten-Architekturen so zu gestalten, dass sie Tools zuverlässig und skalierbar nutzen.
Dieses neue Paradigma, das auf einem proprietären Multi-Agenten-, Mixture-of-Experts (MoE)-System basiert, wurde entwickelt, um sowohl die Zuverlässigkeits- als auch die Skalierbarkeitsherausforderungen direkt anzugehen. Hier ist eine technische Aufschlüsselung, wie Jenovas Architektur, die aus Jahren engagierter Ingenieursarbeit hervorgegangen ist, das Problem löst:
- Mixture-of-Experts (MoE) Routing: Wenn eine komplexe Anfrage eingeht, verwendet das System eine ausgeklügelte Routing-Schicht. Dieser Router klassifiziert zunächst die Absicht des Benutzers in eine bestimmte Domäne. Einige Modelle sind beispielsweise hochspezialisiert auf Informationsabruf-Domänen und zeichnen sich durch das Verständnis von Abfragen und die Verwendung suchbasierter Tools aus. Andere sind für aktionsorientierte Domänen optimiert und beherrschen die Ausführung von Aufgaben wie das Verfassen von E-Mails oder das Erstellen von Kalendereinladungen. Eine dritte Kategorie könnte sich auf analytische Domänen spezialisieren und die Datenverarbeitung und logisches Denken übernehmen. Die Anfrage wird dann an einen spezialisierten Agenten weitergeleitet, der für diese spezifische Domäne am besten geeignet ist, um sicherzustellen, dass das qualifizierteste Modell jeden Teil der Aufgabe übernimmt.
- Multi-Modell-Orchestrierung: Da Modelle von verschiedenen Laboren (wie OpenAI, Google und Anthropic) auf unterschiedlichen Daten und Architekturen trainiert werden, entwickeln sie unterschiedliche Spezialisierungen, die mit diesen Domänen übereinstimmen. Beispielsweise könnte ein Modell, das ausgiebig auf Webdaten trainiert wurde, für die Informationsabruf-Domäne überlegen sein, während ein anderes Modell, das für die Befolgung von Anweisungen feinabgestimmt wurde, in der aktionsorientierten Domäne brillieren könnte. Eine optimale Multi-Agenten-Architektur muss die Flexibilität haben, diese Vielfalt zu nutzen und das beste Modell für jede spezifische Domäne zu verwenden, anstatt an das Ökosystem eines einzigen Unternehmens gebunden zu sein. Jenovas System weist intelligent das am besten geeignete LLM für jede Aufgabe zu und gewährleistet so Spitzenleistung und Zuverlässigkeit in jeder Phase des Arbeitsablaufs.
- Kontextbezogenes Tool-Scoping und Just-in-Time-Laden: Um die Begrenzung des Kontextfensters und das Skalierbarkeitsproblem zu lösen, verwendet die Architektur einen „Just-in-Time“-Ansatz zum Laden von Tools. Anstatt den Kontext des Agenten mit jedem verfügbaren Tool zu überfluten, verwendet das System adaptive Routing-Protokolle, um den wahrscheinlichsten Satz von Tools vorherzusagen, der für den aktuellen Aufgabengraphen benötigt wird. Nur die Schemata für diese relevante Teilmenge werden in den aktiven Kontext des Agenten geladen, wodurch der Denkprozess sauber und fokussiert bleibt. Dies reduziert den Token-Overhead drastisch und ermöglicht es dem System, auf Tausende potenzieller Tools zu skalieren, ohne die Leistung zu beeinträchtigen.
Die Wirksamkeit dieses Ansatzes wird durch Jenovas reale Leistungsmetriken bestätigt. Es meldet eine Erfolgsquote bei der Tool-Nutzung von 97,3%. Entscheidend ist, dass dies keine Zahl aus einem kontrollierten Benchmark oder einer feinabgestimmten Laborumgebung ist. Es ist eine Metrik, die die Leistung in der Produktion widerspiegelt, über eine vielfältige und unkontrollierte Landschaft von Tausenden von Benutzern, die mit einer Vielzahl von MCP-Servern und -Tools interagieren.
Dieses Maß an Zuverlässigkeit zu erreichen, ist nicht nur das Ergebnis einer ausgeklügelten Architektur. Der schwierigste Teil beim Aufbau eines wirklich skalierbaren agentenbasierten Systems besteht darin, sicherzustellen, dass eine unendliche Anzahl verschiedener Tools nahtlos mit verschiedenen Modellen aus verschiedenen Laboren zusammenarbeitet, die alle auf unterschiedlichen Daten trainiert wurden. Dies schafft eine astronomisch komplexe Kompatibilitätsmatrix. Dies zu lösen ist vergleichbar mit dem Bau eines Düsentriebwerks: Den Bauplan zu haben ist eine Sache, aber die Herstellung eines zuverlässigen, leistungsstarken Motors, der unter realen Belastungen funktioniert, erfordert Jahre an spezialisiertem Fachwissen, Iteration und tiefgreifender, gebündelter Ingenieurserfahrung. Diese produktionserprobte Robustheit ist es, was ein theoretisches Design wirklich von einem funktionalen, unternehmenstauglichen System unterscheidet.
Dieser Durchbruch wurde von Schlüsselfiguren in der KI-Community anerkannt. Darren Shepherd, ein prominenter Vordenker und Community-Builder im MCP-Ökosystem, Mitbegründer von Acorn Labs und Schöpfer der weit verbreiteten k3s Kubernetes-Distribution, bemerkte, dass diese Architektur das Kernproblem effektiv löst.

Fazit: Ein architektonischer Imperativ für die Zukunft der agentenbasierten KI
Die empirischen Daten und architektonischen Prinzipien führen zu einer unbestreitbaren Schlussfolgerung: Die Zukunft fähiger, zuverlässiger und skalierbarer KI-Agenten kann nicht monolithisch sein. Das vorherrschende Single-Model-Paradigma ist die direkte Ursache für den Tooling-Engpass, der derzeit den Fortschritt des MCP-Ökosystems und der agentenbasierten KI insgesamt bremst.
Während viele in der Branche versuchen, dies von der Serverseite aus anzugehen, ist dieser Ansatz grundlegend fehlgeleitet, da er das Kernproblem der begrenzten kognitiven Kapazität des Agenten nicht löst. Die wahre Lösung muss agentenzentriert sein. Wie der Erfolg von Jenova zeigt, ist die Lösung dieses Problems möglich, aber es erfordert weit mehr als nur die Verbesserung der Basisfähigkeiten von Modellen oder das Hinzufügen einer leichten Logikschicht. Es erfordert einen Paradigmenwechsel hin zu anspruchsvollen, agentenzentrierten Architekturen, die auf tiefgreifender, gebündelter Ingenieurs- und Architekturkompetenz basieren und sich speziell auf die einzigartigen Herausforderungen agentenbasierter Systeme konzentrieren.